


What is Satori?
Satori is a layer that sits between your users or applications and the data stores they access. It provides organizations with visibility into data flows, granular access control, security and privacy policy enforcement and continuous monitoring. Organizations use Satori to ensure data science teams are not exposed to personally identifiable information (PII) when querying sales data from a BigQuery data lake using Python or that only the EMEA customer success team can access data of European customers in a Snowflake data warehouse using Tableau. At its core, Satori is a transparent proxy service that data consumers connect to instead of connecting to the actual data store itself. Satori is not a query engine or another type of database, it’s a security layer that organizations deploy in front of their data stores. Satori operates at the network level but speaks the language of the data store and is thereby able to deliver a rich set of capabilities.
Satori enhances every data activity with the following context:
- Identity – Satori monitors the creation of new connections to data stores and uses that information to look up the profile of the user in the Identity and Access Management (IAM) system of the organization.
- Data – Satori looks at both the query and the result set to classify the transaction for sensitive information, like names, email addresses and social security numbers.
- Behavior – Satori profiles real-user access in the environment to know what normal access looks like while also delivering a rich set of out of the box behavioral policies that promote good data access hygiene.
For example, in a company that operates in Europe and is required to comply under GDPR, Satori observes a “SELECT * FROM CUSTOMERS” query on a Snowflake data warehouse. Satori looks up the person running the query in okta to discover that he’s an analyst from the finance team that joined the organization 2 months ago. When the result set starts flowing back from Snowflake, Satori detects many instances of PII within the data. Based on the identity context (finance team, analyst), data context (PII in the result set) and behavioral context (new member of the team running an unfiltered query) Satori returns an empty result set back the analyst, potentially alerting his supervisor of the attempt. The range of actions Satori can take is broad and depends on the level of enforcement required by the organization.
How do I start using Satori?
To start routing traffic through Satori, you select the type of data store in the Satori management console and enter its hostname. Satori generates an alternative hostname that points to the proxy service. You can use the new hostname right away in any query tool of your choice, in parallel to your other users who are still using the original hostname.

Original and Satori generated hostnames in the Satori Management Console
By providing the Satori hostname to anyone ranging from a single person to an entire organization, rolling out Satori is a gradual process and regular data access keeps working as normal, side by side. When the rollout is completed, access restrictions should be placed on the original hostname, for example, to block access except for the Satori proxy IP addresses.
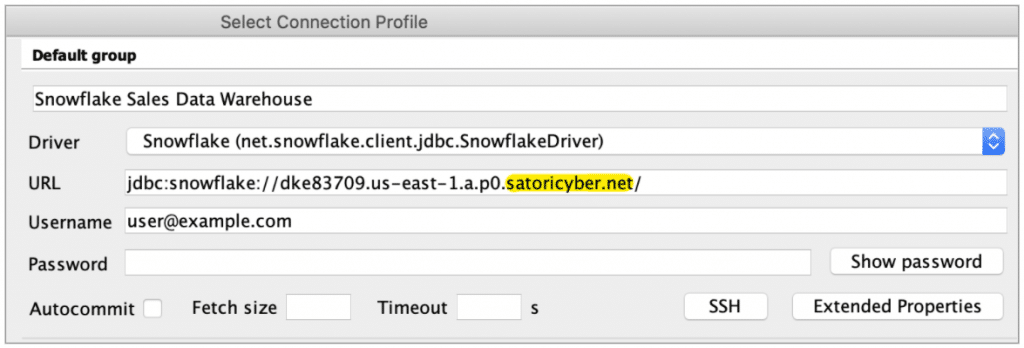
Using the Satori generated hostname in SQL Workbench
Dynamic Inlining
Satori’s architecture is optimized for reliability and low latency. Our approach to solving for that is to separate data traffic into two data paths: proxying and analysis. Proxying means the transfer of bytes from data consumers to data stores and analysis is where we run our algorithms and policy engine. Each path is handled by a separate set of compute resources and, more importantly, separate software with a different codebase and release cadence. For proxying, Satori uses NGINX, a well-known proxy software that has become ubiquitous across the web due to its flexibility and reliability. As an example, Cloudflare uses NGINX to power its Content Delivery Network and other HTTP-related services. We use NGINX’s out-of-the-box capabilities to proxy both TCP and HTTP traffic and to terminate TLS connections. Every Satori deployment includes a highly-available set of NGINX proxy servers as containers in a Kubernetes cluster. Connections between data consumers and data stores only go through NGINX. We’ve very creatively coined our analysis software as the ‘Analyzer’. We built Analyzer using Rust, a system programming language focused on safety, concurrency and high performance. Analyzer’s software is not in the data path between data consumers and data stores. Instead, it receives traffic captures from NGINX using a module we built to facilitate that, and processes them asynchronously. Depending on the policies that are applied to the connection, Analyzer can instruct NGINX to terminate the connection, block a query, return an empty result set or mask sensitive data.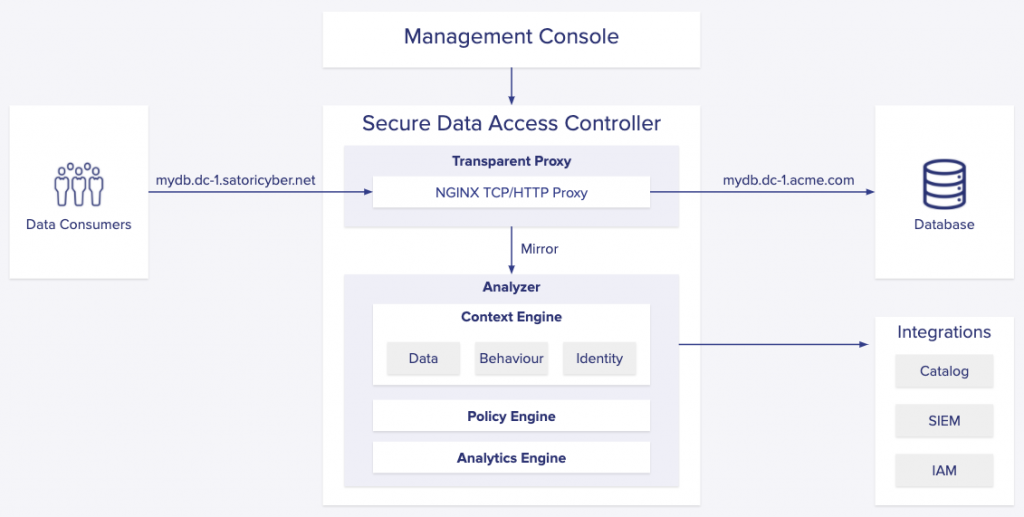
The architecture of the Satori platform
Get our solution brief and stay tuned for future blogs where we share more details about how Satori’s Context, Policy and Analytics engines work.


