Creating and maintaining a data inventory is an important part of a comprehensive data management plan. Data inventories make your data more accessible and help you maintain governance, meet compliance requirements, and reduce security risks. Many modern organizations are using AWS Redshift clusters to fulfill some or all of their data warehousing needs. Additionally, with Redshift Spectrum, organizations can also use Redshift as a query engine for data lake needs, pulling and processing data from S3 storage buckets. In this post, we explore how to automate a data inventory using Redshift so that organizations can utilize more data and increase their data-driven value.
Storing and processing data is one thing, but, with ever-growing and ever-changing data, it is becoming increasingly difficult to gain visibility into what you (as an organization) have and to answer questions such as:
- What personal identifiable information (PII) do we have in our data warehouses and data lakes?
- What other types of sensitive data (healthcare, financial data, etc) do we possess?
- What new data types did we add over a specified period?
- What sensitive data did we recently add to our data repositories?
In a physical warehouse, where you store a large number of items, it is crucial to maintain an inventory. This inventory provides vital information about what you have in the warehouse and its location. The same is true for a data warehouse.
The ability to grow your operations and the large number of consumers both in and out of your organization makes data operations much more agile and intensive. Maintaining an organized, up-to-date and adaptable data inventory is necessary as more people have access to data, and continuously add data of various types.
In this article, we will discuss:
- What is a data inventory?
- How does it differ from a data catalog?
- Why is it important to inventory your data?
- Creating a Redshift data inventory
What Is a Data Inventory?
Similarly to how an inventory for a physical warehouse contains information about the items in the warehouse, where to find them, and their nature, a data inventory is a repository with a metadata collection of the datasets that an organization collects and maintains. It includes the location of each dataset and the type of data each contains.
|
When we use the term ‘metadata’ throughout this blog post, we refer to it in its broader meaning. For example, the existence of a social security number in a certain column and not strictly the numeric data type of that column. |
When we use the term ‘metadata’ throughout this blog post, we refer to it in its broader meaning. For example, the existence of a social security number in a certain column and not strictly the numeric data type of that column.
There are several different reasons to collect metadata:
- provide consumers with information about what they are looking for
- enable organizations to know the location of specific types of data (often a compliance requirement)
- define relevant access policies for each dataset
How Does it Differ from a Data Catalog?
The terms ‘data catalog’ and ‘data inventory’ are often used interchangeably. Sometimes the data inventory of one organization refers to a data catalog in another organization. However, ideally, the inventory is a more technical metadata collection that refers to specific datasets and is granular to the level of columns and data types stored.
In contrast, the catalog is less technical and mainly serves as a directory for the data, providing a good indication of where to locate specific data and who owns the data within the organization. To account for occasional overlaps, different sections of the data catalog may refer to a specific location within an inventory.
Why Is it Important to Inventory Your Data?
Maintaining up-to-date knowledge of what data you have and where it is located is important by definition. If you do not know what you have, it becomes much harder to derive value from your data. In addition, it will take consumers longer to understand what data they need, what data the organization already has, and where it is stored. Lacking this clear understanding can delay projects and incur costs. For example, it can lead to the creation and processing of multiple copies of the same data by different teams.
In addition, having a data inventory is important for complying with protection and privacy regulations. Such regulations, including GDPR, require companies to know where their sensitive information, especially PII, is stored.
Why Is it So Difficult to Maintain a Data Inventory for Redshift?
Keeping a regular data inventory is not a walk in the park. Typical uses of Redshift are often very complicated. This is because, in many cases, multiple users (often from different teams) are storing data within the warehouse. The data often rapidly changes, as it is copied from one location to another with varying levels of sensitive information.
This process is even more elaborate when Redshift is used as a data lake, as this increases the amount of data stored and the data’s complexity (as there are different types of files, often with semi-structured data).
Creating a Redshift Data Inventory
Regardless of the reason, there are several ways to create a data inventory for your Redshift, each with its own advantages and disadvantages. Let’s consider the options:
- Creating a Manual Redshift Data Inventory
- Creating a Redshift Database Scanner-Based Data Inventory
- Using Satori for an Autonomous Data Inventory
Creating a Manual Redshift Data Inventory
Often, a very straightforward way to build an ad-hoc data inventory is by querying your metadata tables. Thankfully, in Redshift, based on the Postgres engine, the metadata is kept in a single centralized location, namely the information_schema.columns table, so we do not need to iterate over several tables. Rather, we get all of our columns from there by, for example, running the following query:
The query above retrieves a table with the column name and location (table, schema, and database), sorted by its ordinal position within each table, schema, and database. The result is something like this, taken from a TPC-H schema:
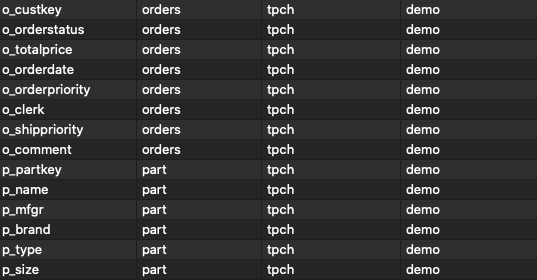
You can use this data as a basis for adding more metadata. Depending on the use case, this method may require writing a script or an application to pull this data from different clusters and make sense of it all by adding information about owners, data types, and descriptions. In some cases, this will involve copying the data into a spreadsheet. In other cases, there is no need to drill-down to the column level, so only tables are pulled from the metadata.
Keep in mind that the list is static and therefore only correct for the moment of its creation. If someone creates or modifies the schema at a later point in time, the metadata is now outdated. If you want a more agile solution, you probably need to write a script to pull updates from your clusters or choose a different option.
Creating a Redshift Database Scanner-Based Data Inventory
There are multiple open source and commercially available offerings for this purpose. These products are useful to build, enhance, and structure the inventories of your databases. The products and services include Alation, Collibra, Informatica, and others. Alternatively, you can utilize AWS Glue for crawling and retrieving the metadata from Redshift. You can employ these products to periodically scan your clusters to retrieve the metadata.
Scanning the data with these solutions also contributes to data stewardship and using the metadata as a system of records for data access policies. Keep in mind that, if the data changes frequently, the integrations become more complex to manage, and manual data access request audits can be challenging to supervise at scale.
This complexity, especially because data is ever-changing, led us to design our autonomous data inventory in a way that does not require additional work as the data evolves.
Using Satori for an Autonomous Data Inventory
After speaking with dozens of data engineers, architects, stewards and governance professionals about the benefits of having an up-to-date data inventory, which includes sensitive data locations in warehouses and lakes, it became clear that organizations need updated data inventories but often lack them (especially a good one which includes data classification).
We took this feedback into account when we built Satori. We wanted it to work autonomously, not burden data operations teams or become an ad-hoc project. Our goal is to continuously update the data inventory without requiring configuration or integration time.
Satori continuously monitors data access, identifies the location of each dataset and classifies the data in each column. The result is a self-populating data inventory, which also classifies the data for you and allows you to add your own customized classifications on top:
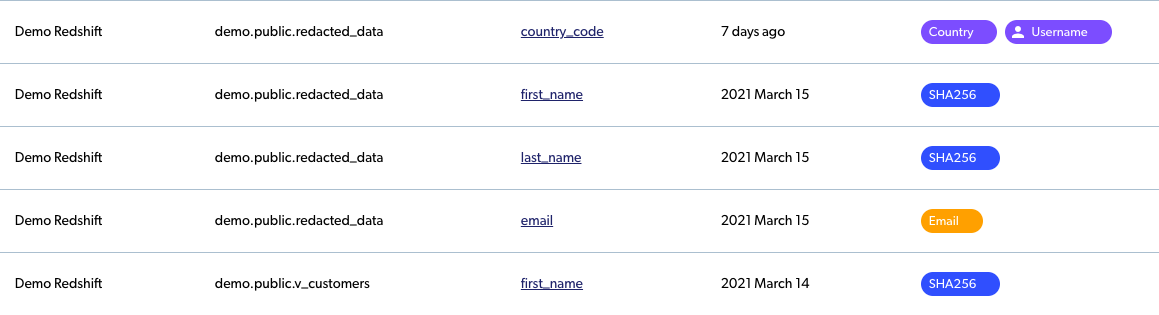
If our approach sounds intriguing, you can read more about how we implemented Satori’s Autonomous Data Inventory here.
Conclusion
A data inventory solves a lot of problems. It makes your data more accessible and helps you maintain governance, meet compliance requirements, and reduce security risks. You need to decide how you want to solve this problem - with a homemade manual solution, an integrated scanning solution, or Satori’s autonomous data inventory.
Satori's autonomous data classification and discovery is easy to implement as it does not require any additional configurations. To learn more about how Satori can help you automate this process schedule a demo with one of our experts.