The concept of treating data like a product burst into the collective consciousness of data professionals in large part thanks to the incredible popularity of Zhemak Dehghani’s socio-technical concept, data mesh.
For those unfamiliar, data mesh is a decentralized but interoperable data architecture and operating model that emphasizes domain-oriented ownership of data, a self-serve data platform, federated governance, and “product-thinking” applied to data.
However, regardless of your data architecture or team structure of choice, shifting your mindset and organizational culture to one that treats data like a product can have a profound impact. Creating highly reliable, easily accessible, and strongly governed data products increases data adoption and ultimately the value of your organization’s data.
But you can’t just declare this shift, you need to live it. Here’s how.
What Exactly is a Data Product?
Before we dive into exactly how to treat data as a product it can be helpful to define exactly what we mean when we use the term, “data product.” This isn’t a reference to a fully developed SaaS application.
Most data teams will adopt an expansive definition of data product that includes key datasets, critical dashboards or decision-support tools, and machine learning algorithms. The most common “atomic unit” of a data product is a production table as standards across reliability, interoperability, access and discovery are easily scaled.
Not every table, pipeline or data asset needs to be deemed a data product. Ad-hoc requests are a reality across the modern enterprise. The data product label can be reserved for your most important assets and used as a means to focus and prioritize your team’s efforts.
How to Treat Data Like a Product
An expansive definition of the type of data asset that constitutes a data product can be helpful as these methodologies continue to mature–as long as the reliability and governance standards are firm. Here are four of the most important.
Clear Lines of Ownership
Clear lines of ownership are important for obvious reasons. If everyone is accountable, then no one is actually accountable. It accelerates incident resolution, access management decisions, and creates clear lines of communication.
Ideally, ownership is established at the organizational, product, and dataset level. At the organizational level, it’s important to determine accountability for major initiatives like data mesh or a data governance program, as well as the key stakeholders across the business who will be consulted and informed.
To establish ownership at the product level, many leading data teams have introduced the role of “data product manager.” While historically this ownership might have been at the project level, this data professional typically oversees the roadmap of projects that fall within the scope of a long-lived data product, and aligns the organization with the overarching vision of the product.
They often tackle tasks that build long-term value but aren’t in the purview of the typical day-to-day work of the data engineer. This includes acquiring user feedback, gathering team requirements, identifying build versus buy decisions for the team to evaluate, building feature roadmaps, and more.

Finally, it’s important to have owners for each production dataset on the data team, as well as a clearly defined partnership with the data producers – often product engineering teams – on which the datasets rely. There needs to be someone on the hook to resolve issues when they arise, and while these issues may be technical or organizational, often they are intertwined.
Data SLAs
Data engineers need to measure data downtime just like our friends in software engineering who have addressed application downtime with specialized frameworks such as service level agreements, objectives, and indicators (SLA, SLO, SLI). With SLAs, different engineering teams and their stakeholders can be confident they’re speaking the same language and sharing a commitment to clearly documented expectations.
A data SLA should specify the who, what, where, when, why, and how of a data pipeline. In other words:
-Who is affected by this dataset?
-What are the expectations of this data?
-Where is the data?
-When does the data need to meet the expectations?
-Why is this data SLA needed?
-How will we know when the data SLA isn’t met? How should the data team respond
Data teams may also choose to create different reliability tiers for their data products with each tier having more stringent SLAs. Once established, understanding each data product’s SLA adherence can help prioritize effort and resources toward fixing “hot spots.”
Automated Data Monitoring
To uphold a data SLA, data teams must have a means for monitoring both the data and data pipelines to determine when expectations aren’t met and issues arise. This can be built internally, but many teams will leverage a data observability platform to alert for issues like:
- Freshness: Did the data update when it should have?
- Volume: Are there too many or too few rows?
- Schema: Did the organization of the data change such that it will break downstream systems?
- Quality: Is the data within an expected range? Are there too many NULLs, not enough unique values, etc.
By leveraging custom and machine learning monitors, data teams can free themselves from the insufficient, yet time consuming process of unit testing. Data observability platforms also provide incident resolution features like data lineage, which can help data teams quickly identify the root cause by finding the most upstream table impacted as well as understand the downstream impact of an incident for smart triaging.
Data observability can reduce data downtime by 80% while dramatically reducing the time data engineers need to spend on data quality related tasks. Just like applications like e-ticketing weren’t common until the systems supporting them were highly reliable, teams will not be able to unlock the full value of their data until their data products are as reliable as the applications they support.
Automated Data Governance
The shift to treating data like a product may also require a shift in your team’s processes and data platform. Just like DevOps improved application performance by mandating the collaboration and continuous iteration between developers and operations during the software development process, DataOps can help data teams take an automation-first approach to building and scaling data products.
One of the most important first steps to building reliable data products at scale is building the modern data platform that is going to enable the development of data products. This typically consists of several integrated solutions such as:
- Storage and processing: The heart of the platform is the warehouse and/or lake
- Ingestion, transformation and orchestration: These solutions help to extract and load data, clean and model it, and automate these data pipelines to run on set schedules while managing dependent processes
- Access and activation: This could include solutions for business intelligence, experimentation and making the transformed data available to external tools for targeted marketing campaigns or tailored messaging
- Data observability: Ensuring reliable data at scale
- Governance: Managing permissions and access to data, as well as making data discoverable for end users
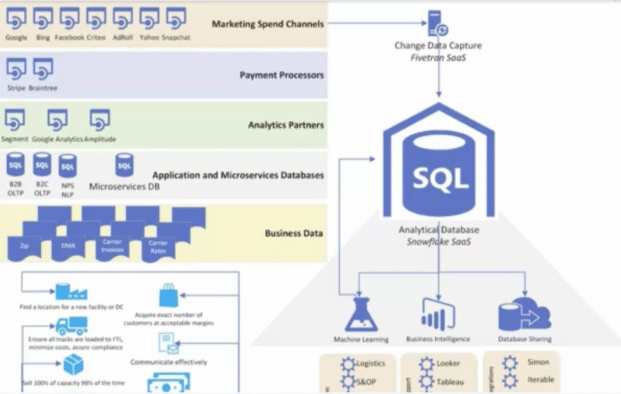
Curious about how to build a modern data platform? Check out this post or webinar on how Freshly built their platform to improve trust in data at scale. The following diagram displays Freshly’s data platform.
Take it Seriously
Data has become more valuable, which conversely means downtime or access breaches have a higher severity. Don’t treat data like an afterthought, treat it like a product.