There are moments when architecting data where you need to make decisions that will have broad implications in the future. In many cases, such decisions lead to the requirement for specific access control mechanisms, which often becomes the catalyst for the need of Row-Level Security - a choice for certain data architectures. In this blog post, I will share some use-cases that drive the necessity for row-level security, as well as demonstrating how Satori helps solve the problem in a revolutionary way. In the past, I also gave examples of setting up row-level security in platforms like Snowflake and Redshift.
So… what IS row-level security?
Row-level security has several different names, such as Row-Level Access Control, or Row Based Security. In general, it describes a situation where there is tabular data, and certain users or groups of users should have limited access to that said data. The most simple diagram is this, where each user can access a certain portion of the rows in the table:
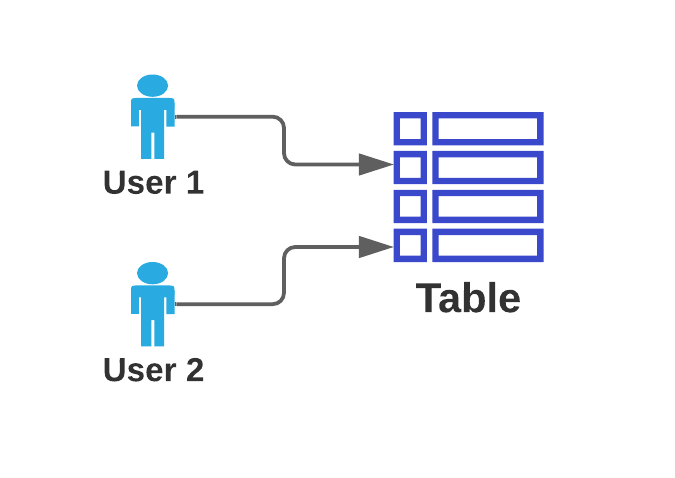
Access to the data is restricted according to a Row-Level Identifier, which is a value or set of values that is typically an identifier in one of the columns. As we will see in the examples below, this will depend on the exact situation. Based on the circumstance, you may or may not require an additional resource that will link the value in the row level identifier to the access restrictions per user or group of users.
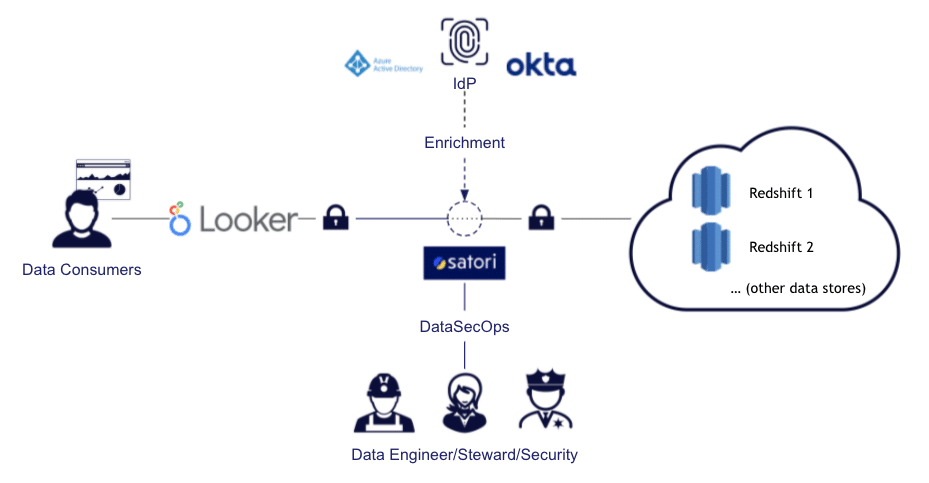
| Satori and Row-Level Security Satori helps solve Row-Level Security issues for existing and new data architectures. Using Satori requires no installation or changes to the data store itself, and it is implemented when retrieving the data. This allows adding Row-Level Security in a very convenient and flexible way, even for relatively complicated scenarios, such as the ones listed below. If you are new to Satori, you can learn more about what we do here. When setting up row-level policies in Satori, you can tag data to add context to the Satori Data Controllers when that data is being accessed. You can then set policies to specify specific actions to be taken in certain scenarios. For example, in the tags, we can define the situation (i.e., filtering over a specific column), and determine in the policy what the action will be (i.e., block access if certain filtering is non-existent). |
Row-Level Security use-cases
Not all Row-Level Security architectures are made the same, and not all of them are a simple column specification that determines which user ID is able to access which row. Here are some examples to take into consideration:
Basic Row-Level Security
At the basic level, there is a table or set of tables, where a certain column acts as the row identifier, to make decisions about allowing or denying user access to the data in that specific row. This can be an ID number, which identifies the group of users who should be allowed to access the data. A common use-case is in investment companies, where certain analyst teams should only have access to the data of the portfolios they’re managing, not other teams’ data.
Let’s walk this through this investment firm example,where each transaction has an analyst_bucket column, specifying the analyst team who owns the record. As mentioned above, when setting up row-level security in Satori, we need to define tags to give context to the data access.
1. Setting up the mapping tags in Satori
In this case, we can set up a tag that will tag the data access when it is filtered by a certain field. From there, we want it to create a mapping of the column value, and indicate how it’s represented in a tag. An example would be:
In addition, we will create another tag configuration to tag all the tables in which we want to enforce row-level security:
In the below example, we can see that all data access that will filter by the column analyst_bucket will be tagged accordingly. This is detached from the actual data storage technology and will work whether it’s on Snowflake, Redshift, or other data stores. So, if we query the database with the following query...
...this will be mapped, and tagged with the tag filtered_by_c. It should also be tagged by the Customers Data tag, as the data was in one of the tables configured to that tag. If we look in the Satori management console under Audit and expand the tags section, we see that the data access indeed was tagged with the appropriate tags:

If you want to drill-down into this example, you can request a free demo of Satori, or go to our documentation for more information about tags.
2. Setting up the mapping tags in Satori
Using the same example, let’s now set a policy so that we can enforce this row-level security. This policy will be enforced regardless of which datastore is used by your organization (Snowflake, Redshift, Postgres, BigQuery, etc). The policy which we will use is the following: stating that users must filter their queries by the analyst_bucket column (explicit row-level security). In other words, if you try to access a table tagged with the customer_data tag, and you’re using the Snowflake role of team C, you must include a filter on the analyst bucket so that the filtered_by_c tag is applied:
This particular example is quite simple to apply and is easily automated by using our API to generate the required tag maps and policies. This example is also applied based on the Snowflake database role used, but it can also be applied by other identity tags, such as IdP groups.
Now let’s discuss some more adventurous use-cases of row-level security…
Row-level security for semi-structured data
This use-case is when you have tables with some of the columns containing semi-structured data within them, and the filtering criteria for the access control are within the columns in json format. An example would be when a table contains events from different systems, and the users should only be allowed access to the data that “belongs” to their team within the semi-structured json data.
The layout here would be slightly different, but it would still be possible and easy with Satori. Needless to say, we would love to assist you with more exotic tagging like this one:
In this case, the policy would remain the same, as the only thing that changes is the way you describe the data. However, you’re still doing the same thing once you tag it correctly, which is to block illegal access attempts.
Hierarchical Row-Level Security
Another cool example of Row-Level Security are scenarios where you need to apply several layers of access level over the data. For instance, say you have different analyst teams, but you also have regional managers who should be able to pull data of the teams that report to them yet not from other regions’ teams.
Satori is quite flexible about ways to sort out such issues as that, but in our example, we will simply create an additional tagging to be applied for the regional manager. This means they will only be able to see the data of teams A and B, but not other teams:
In this example, the tag mgr_filter_ab will be applied whenever there is a filtering of data for analyst_bucket 1, analyst_bucket 2, or both. So all the following examples will tag the data with the appropriate tag:
Furthermore, you will also see the following tags when going to Satori management console to look for the query in the audit:

Setting up a policy is very similar as the team row-level security:
Other use-cases for Row-Level Security
There are many other use cases for row-level security, such as:
- sometimes used for multi-tenancy (i.e., storing data of multiple tenants in the same table).
- used to enforce regional separation (i.e., making certain teams only able to view data specific to their region).
- giving access to certain logs so only specific users or teams can view certain log entries.
- applying a “safety net” over a “Right To Be Forgotten” (RTBF) policy, so data about certain data subjects will be inaccessible.
Applying Row-Level Security with Satori
As we’ve seen, applying row-level security with Satori is quite simple once you learn the basic concepts of data tagging and policies (and hey, we’re here to help you do that!). Overall, the advantages over doing the same in the data infrastructure itself are:
- Policies and tags are decoupled from the datastore and can be applied across several instances easily, even if they’re using completely different technologies.
- Policies can be added or managed by security teams, data stewards, and data owners, not just the database administrators.
- You can roll-out the policies in a more granular/soft way. For example, you can set them to work in alert mode only, which is impossible in most databases.
- As you need to enhance your access control, you don’t need to edit data abstraction layers, which can be hard and risky.
You can also configure row-level security in some BI tools, but that will be attached to the specific BI tool that you’re using. That means that a simple lacking feature that causes analysts to use other BI tools or a Python script will not go through the row-based security policies.
If there is a use-case for row-level security which you’d like to discuss, whether it’s covered in this post or not, we invite you to schedule a demo.