Today, we are announcing a new service to provide data leaders with autonomous Data Inventory across any cloud data store. This launch will help enterprises simplify their data governance programs by streamlining data access policies with easy, out-of-the-box data tagging and a complete, up-to-date data inventory.
This allows you to easily implement data access policies based on tags in line with your data stewardship principles, generate compliance reports of all sensitive data locations, and run risk assessments across all data stores.
With the new Autonomous Data Inventory, companies who are required to govern their sensitive data for privacy, legal, and security reasons can stop wasting time on ad-hoc manual data engineering tasks attempting to map users to tables and data types. This advantageous capability is now available for anyone using Satori.
How Does It Work?
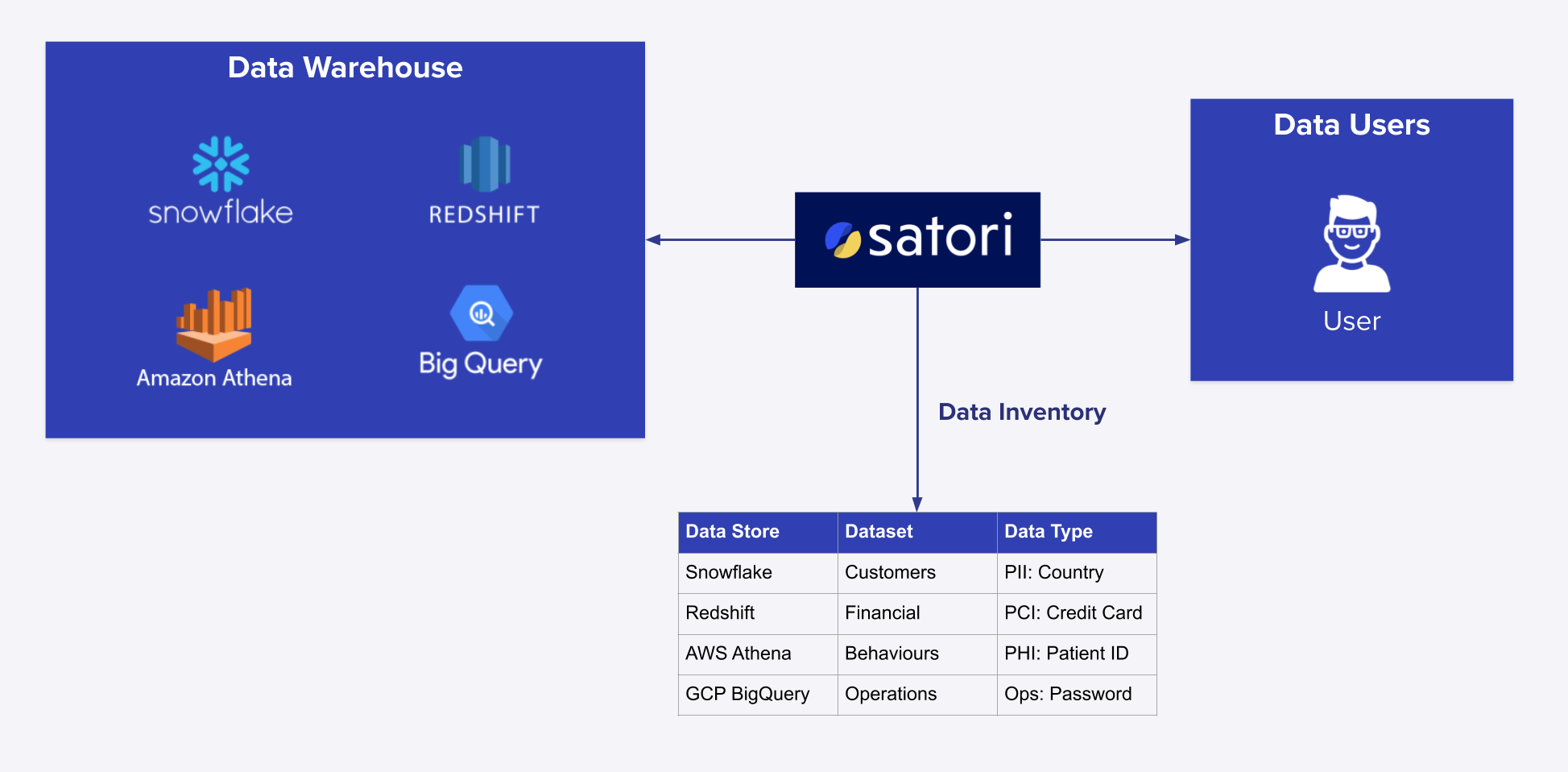
Satori functions as a layer between your data consumers and data stores, in a similar manner as a proxy. It inspects every transaction, classifies the data-in-motion, adds identity context through IAM solutions or data store users and roles configurations, and provides granular access control policies and centralized analytics for all cloud data stores. Once you add Satori to an existing environment, it records all transactions including the data location, data type, user, and role. Starting today, it also builds an autonomous and classified inventory of all used data, so, every time a query retrieves data from an unfamiliar location, Satori automatically updates the inventory accordingly (in real-time) with the following context:
-
Location of the data, based on querying the database metadata in the background. Below is an example of the type of query Satori utilizes to identify a data inventory location, for a given table location e.g. db1.schema1.table1:
- Type of data, based on Satori’s out-of-the-box data classification
- Who is accessing the data, based on identity context from the database or your IAM
The Data inventory is available in the Satori management console and Satori users can easily browse through it and search for specific data types across all data stores. So answering questions like in which locations PCI data is stored? becomes immediate and straight forward to answer with just a few clicks.
How to Get Started?
In the Satori management console navigation menu on the left hand side of the screen, you will find a new item labeled ‘Inventory.’ Navigate to this tab to explore all data locations or filter for specific locations using the following criteria:
- Data Stores
- Generalized data categories such as PII, PHI, and PCI
- Any granular data tags such as Medical Record Number, Credit Card Number, Social Insurance Number
The Satori real-time data inventory is self-sufficient and evolutionary—you do not need anything else to begin exploring which types of data are in which locations. No credentials, scanners or agents are needed.
In addition, adding new data tags for specific columns is a simple process. By clicking ![]() , you can add a new tag to an existing column which can be used for more effective access control policies and analytics.
, you can add a new tag to an existing column which can be used for more effective access control policies and analytics.
What's next?
Our goal is to simplify data governance tasks, so we are focused on continuing to add capabilities that streamline the daily data operations activities. Managing an identity context between IAM hierarchies and data stores roles may inhibit enterprise data engineering teams from streamlining data access. Therefore, we are working on organizing data consumers identities in order to provide data access policies in a cleaner, simpler and more effective manner. Stay tuned!