

When data engineers and other professionals experience Satori for the first time, one aspect they become very excited about is the ability to see how their data is automatically classified. Specifically, their emphasis is on classifying different types of sensitive data, such as PII, PHI, and financial data, out of the box. This sensitive data discovery happens continuously, and new sensitive data is discovered as it’s being accessed, with zero configuration needed.
In software development, these moments in which unique technological capabilities meet the users’ needs are precious. Since introducing our continuous data classification, we at Satori have been further exploring how to improve our data discovery capabilities and solve more pain points for data-driven organizations to help them win with data.
One idea that arose from many of our innovative, data-driven customers is the need to not only discover and classify our own “taxonomy” of sensitive data but also to allow customers to teach us their individual classification of sensitive data. In other words, these customers would like to teach Satori some custom data types that are specific to their organization and then have Satori discover these for them. This discovery can consequently be performed on the existing data, but it also be applied to any newly added data.
Why Use Custom Classification?
We provide our customers with a platform along with building blocks that allow them to simplify their data access. We would not be surprised if we begin seeing this capability implemented in new and novel ways, but here are some of the common use-cases we have seen for custom classification:
Specific Types of Sensitive Data
Several companies have specific types of data on which they would like to keep track. Sometimes, this data may be sensitive, such as unique identifiers of customers, employees, or patients. On the other hand, this data may not be directly sensitive, but it can still be something you want to report on, such as campaign identifiers or pricing information.
By allowing customers to define such classifiers, Satori will ensure that this data is discovered from that point forward, whenever and wherever it arises. This feature includes all data platforms where Satori is configured as the data access controller, and it even includes semi-structured data.
For example, ACME Corporation has a specific way in which employees are identified, across all company assets, which is:
“emp”-<branch number>-<employee number>
For example, an employee in the NYC branch, branch 212, with employee number 1337, will have the following employee identifier: emp-212-1337.
This data type (which can be referred to as “Employee ID”) is specific to ACME Corporation and will not make sense in other organizations, which may use an alternative identifier. Nevertheless, specifically for ACME corporation, this identifier is important and can have significant use-cases over their data assets.
ACME Corporation may want to limit the exposure of the specific employee IDs to certain teams and partially mask it for others. For example, by taking advantage of Satori’s dynamic masking capabilities, depending on the identity of the data consumer, the team may get access to the exact employee ID (“emp-212-1337”), a hashed result, or a completely redacted result.
Example: Teaching Satori to Identify Employee IDs
To accomplish this task and gain the ability to identify employee IDs across ACME corporation’s data estate, you should follow the subsequent simple process within Satori (for the sake of simplicity, we will use the User Interface, but you can also use Satori’s REST API):
- Head to Data Inventory, and, from the upper menu, select “Taxonomy Tree” and then “Add Category” (+):

- Choose an appropriate name and description for the category as well as a color that will be used for tags in this category, like in the following example:

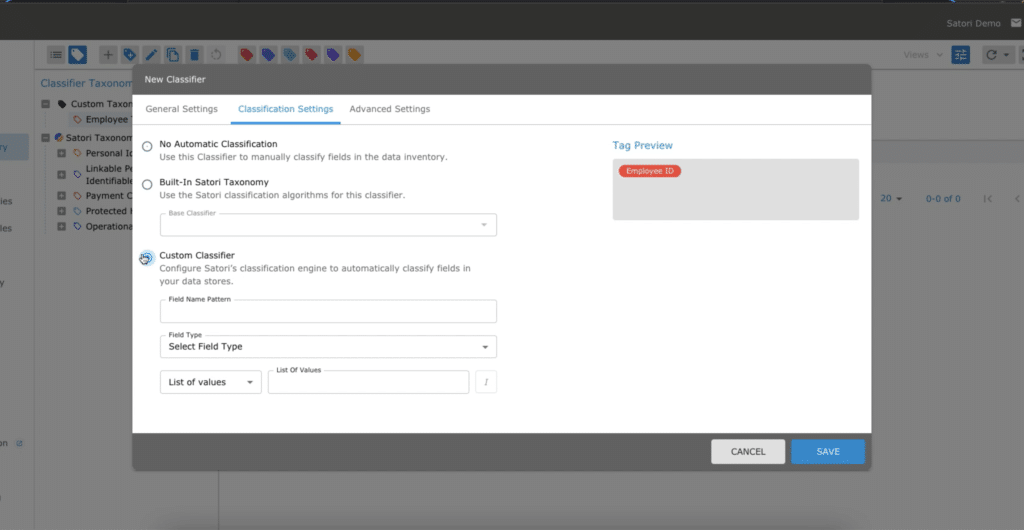
- Next, choose the category in the taxonomy tree and click “Add Classifier.” We will call the classifier “Employee ID,” as per our example.

- Under the Classification Settings tab, let’s define the following RegEx (Regular Expression) to describe the pattern we are looking for to discover an employee ID:
In the RegEx, we used (emp-d+-d+), each d+ denotes a digit with one or more repetitions. This classification can, of course, be something more specific (such as emp-d{3}-d{4} which forces a 3-digit region and 4-digit employee number) or something more generic.
- When we send the following query:



|
SELECT emp, order_num FROM employee_orders; |
We getting items that should be classified as Employee IDs:

And, indeed, this output is the audit record in Satori, showing the custom tag which was tagged by Satori through scanning the content of the query:

At the same time, your data inventory is also updated, and you now know that this location holds Employee IDs.
Specific Taxonomies
In addition to the ability to add specific tags and “teaching” Satori how to classify data as this specific type, you can create complete taxonomies to match your business needs. Once you create these sets, this addition can blend a strong business sense into your data assets management.
For example, you can group different data types that all belong to one of your regulations or compliance frameworks and then have all these data types categorized and tidy for your next compliance audit or report.
Using the Tags in Security Policies
The next step in your DataSecOps journey, after teaching Satori about custom data types that have specific business meaning in your environment, may be to apply security policies, which will be applied to all such data.
Let’s continue with the Employee ID example and create a simple masking profile that redacts Employee IDs. In this situation, this is what the masking profile looks like:

We can now use this masking profile in a Satori security policy, and perform this redaction to Employee IDs:

A Simple Section About Simplicity
You can accomplish many things without complex policies. However, it is precisely when things are simple that you can be extremely effective in your security policies. That is, by simply teaching Satori what an employee ID is (as per the example, but, of course, this can be any other data type as well) and then applying a corresponding security policy, you do more than simply“get the job done.”
Your security policy, as well as the entire process, is now crystal clear across all of your various data platforms. And that is a REALLY sweet spot to be at!
The Sky’s the Limit
For the purposes of this article, I used quite a simple example where a company wants to “teach” Satori what an Employee ID is, tag it, and act upon it (by masking it to unauthorized users).
These limitations and controls are usually components of a larger security policy. For example, all employee details will be masked as part of a single masking profile, and they will be applied together as part of a single security policy. You may even want to use custom tagging as building blocks to apply smart (and simple!) row-level security.
Whatever your specific data access business needs are, we would love to hear about them and explore how Satori can help you. If you would like to schedule a demo with us, fill out the form below.


