“Implementing data security controls for specific users and groups is so complex,” an Enterprise Data Architect shared with me. “We have a strategic objective for utilizing our data for the benefit of our company, so we must make data available and easily accessible for our internal data users. To achieve that, we went on and rebuilt our entire data stack and adopted the latest cloud data platforms only to find out that security, privacy, and compliance requirements are growing so fast that our speed-to-data remains flat despite the huge investment we put into technology and people”.
This sentiment is a common theme in data security which repeats itself over and over again: companies with a vision of enabling broad access to data get stuck in a reality where their engineering queue is filled with tedious tactical operational and security tasks of building DB views, maintaining mapping tables, and developing functions in an attempt to keep data entitlements under control.
This observation indicates a gap for data teams, as there exists no holistic design model to help define security policies that can scale to meet the demands of enterprise data architectures. To solve this problem, we went on and extended Satori’s proxy architecture to close this gap. Last month, we announced Self-Service Data Access, and, today, we expand Satori’s DataSecOps platform with a new Data Security Policy Engine to scale data security policies across an enterprise with reusable policy objects.
With this launch, we help scale data security operations for dynamic enterprise data environments using universal and holistic security policies. This means that you will be able to define and manage row-level security, column-level security, and masking policies globally across all data locations at once.
This capability is now available for anyone using Satori.
Why Data Engineers Despise Data Security
Let’s consider ACME, a global retailer that operates in multiple geographies, serves subjects from different regions, stores their personal data, and buying habits. ACME also has multiple regional data analysts and scientist teams tasked with developing analytics and ML models for optimizing operations, supply chains, and increasing ACME’s sales.
ACME’s security policy dictates that data consumers of a specific team (e.g. US) should not be able to access subjects’ data from other regions (e.g. EU). This policy sounds straightforward and standard, nothing too sophisticated or fancy.
However, if you have ever tried to implement a policy of this kind in an enterprise data environment, you would have learned from your experience that it is not as simple as it sounds, and matters escalate quickly to a high level of complexity.
Most organizations would try to implement such a requirement by providing users entitlements to custom views according to a predefined user mapping to role or team affiliation. This system will work as long as the organizational environment is stable. In reality, though, enterprise environments are dynamic and frequently change as new data sources are added, new security requirements emerge, and data consumers change roles and move between teams on a daily basis. This means such an implementation will quickly become obsolete and will require ongoing maintenance by busy data engineers who have better things to do than updating mapping tables and building the same type of DB objects every time an employee moves between teams.
To introduce a level of abstraction into this process, data platform vendors have been equipping data engineers with tools and features to automate some parts of the process. For example, Snowflake just added an implementation for Row-Level Security (RLS) on a schema level, Microsoft SQL Server and Azure Synapse come with their proprietary implementation of Row-Level Security, and AWS relies on its Redshift users to implement RLS on the BI layer. Other security control features such as data masking have their own implementations and require data engineers to use a combination of proprietary functions and homemade development.
So, can there be a different way to manage data security policies in a way that fits dynamic enterprise data environments and also relieves data engineers from the associated operational tasks?
We believe the answer is yes, and that is why we built Satori’s DataSecOps policy engine in a way that lets you add policies such as row-level security on top of existing datastores in a seamless and non-intrusive manner.
How to Get Started?
Ready to set your first Satori security policy? Let’s see an example of how you can simply define a row-level security policy that will apply to data consumers of ACME’s EU and US teams:
In order for our policy to apply to all data locations (not just one table or schema) and to be resilient to changes in user team affiliation, we will define two types of objects in Satori - a Dataset, that includes all data locations which contain customer data and two Directory Groups, one for each team.
Read more about configuring Security Policies and Directory Groups in Satori.
Next, we add a row-level security policy that defines how data should be filtered by the region column for each of our US and EU users. You can add as many data locations as needed to a single policy. Here’s how to configure this policy in the Satori UI (yes, you read correctly: Satori provides a user interface for defining security policies so not only data engineers can to that):
Read more about configuring Security Policies in Satori.
The last step is to select which security policies should be applied to our dataset. In the dataset security policy configuration tab, select one or more policies, and Satori will take care of the rest. In the screenshot below, we chose to add the above Regional Access policy. You can apply the same policy to any number of datasets. In the case of a change to an existing policy, you would only have to update the object once, and it will automatically apply to all relevant datasets. So, if a new APAC team is added, you just add it to the same security policy definition with a few clicks, and you’re done.
That concludes the required configuration, and, from now on, US and EU users who access regional data across all data locations will only see records relevant for their region.
How Does Row-Level Security Work?
Let’s dive into how the row-level security policy above is implemented behind the scenes in Satori. In this example, I will use Snowflake, but Satori works in the same way across any other DB.
Let’s say the user starts by running the following query:
SELECT * FROM orgdata.private.customers
Satori then evaluates the following questions before letting the user access the data:
What is the user’s identity? The user is a member of the “US Users” directory group through his affiliation with the Snowflake US_TEAM role.
Which dataset is accessed? The customers' table is part of the “Regulated Customer Data” dataset.
Should any security policy be applied? Yes, this user’s access should be limited to records of the “us” region only.
Based on the answers to these questions, Satori rewrites the SQL query sent to the data store, at the time of access, and adds a WHERE clause to filter the transaction only to “us” records the user is allowed to see:
SELECT *FROM orgdata.private.customersWHERE orgdata.private.customers.region IN ('us')


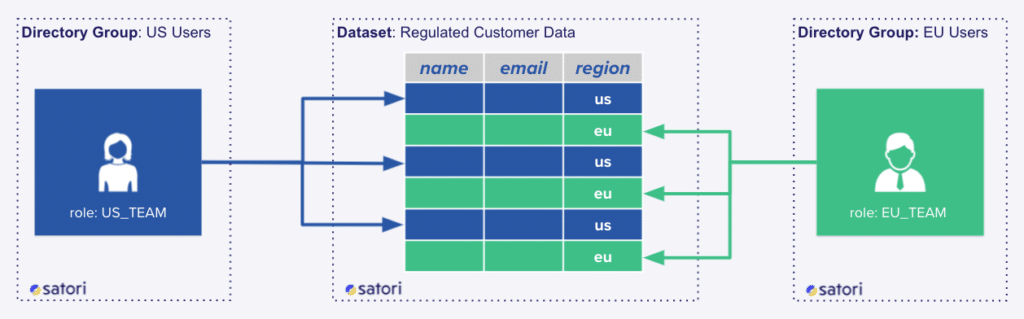
 In order for our policy to apply to all data locations (not just one table or schema) and to be resilient to changes in user team affiliation, we will define two types of objects in Satori - a Dataset, that includes all data locations which contain customer data and two Directory Groups, one for each team.
In order for our policy to apply to all data locations (not just one table or schema) and to be resilient to changes in user team affiliation, we will define two types of objects in Satori - a Dataset, that includes all data locations which contain customer data and two Directory Groups, one for each team.
 Read more about configuring Security Policies and Directory Groups in Satori.
Next, we add a row-level security policy that defines how data should be filtered by the region column for each of our US and EU users. You can add as many data locations as needed to a single policy. Here’s how to configure this policy in the Satori UI (yes, you read correctly: Satori provides a user interface for defining security policies so not only data engineers can to that):
Read more about configuring Security Policies and Directory Groups in Satori.
Next, we add a row-level security policy that defines how data should be filtered by the region column for each of our US and EU users. You can add as many data locations as needed to a single policy. Here’s how to configure this policy in the Satori UI (yes, you read correctly: Satori provides a user interface for defining security policies so not only data engineers can to that):
 Read more about configuring Security Policies in Satori.
The last step is to select which security policies should be applied to our dataset. In the dataset security policy configuration tab, select one or more policies, and Satori will take care of the rest. In the screenshot below, we chose to add the above Regional Access policy. You can apply the same policy to any number of datasets. In the case of a change to an existing policy, you would only have to update the object once, and it will automatically apply to all relevant datasets. So, if a new APAC team is added, you just add it to the same security policy definition with a few clicks, and you’re done.
Read more about configuring Security Policies in Satori.
The last step is to select which security policies should be applied to our dataset. In the dataset security policy configuration tab, select one or more policies, and Satori will take care of the rest. In the screenshot below, we chose to add the above Regional Access policy. You can apply the same policy to any number of datasets. In the case of a change to an existing policy, you would only have to update the object once, and it will automatically apply to all relevant datasets. So, if a new APAC team is added, you just add it to the same security policy definition with a few clicks, and you’re done.
 In order for our policy to apply to all data locations (not just one table or schema) and to be resilient to changes in user team affiliation, we will define two types of objects in Satori - a Dataset, that includes all data locations which contain customer data and two Directory Groups, one for each team.
In order for our policy to apply to all data locations (not just one table or schema) and to be resilient to changes in user team affiliation, we will define two types of objects in Satori - a Dataset, that includes all data locations which contain customer data and two Directory Groups, one for each team.
 Read more about configuring Security Policies and Directory Groups in Satori.
Next, we add a row-level security policy that defines how data should be filtered by the region column for each of our US and EU users. You can add as many data locations as needed to a single policy. Here’s how to configure this policy in the Satori UI (yes, you read correctly: Satori provides a user interface for defining security policies so not only data engineers can to that):
Read more about configuring Security Policies and Directory Groups in Satori.
Next, we add a row-level security policy that defines how data should be filtered by the region column for each of our US and EU users. You can add as many data locations as needed to a single policy. Here’s how to configure this policy in the Satori UI (yes, you read correctly: Satori provides a user interface for defining security policies so not only data engineers can to that):
 Read more about configuring Security Policies in Satori.
The last step is to select which security policies should be applied to our dataset. In the dataset security policy configuration tab, select one or more policies, and Satori will take care of the rest. In the screenshot below, we chose to add the above Regional Access policy. You can apply the same policy to any number of datasets. In the case of a change to an existing policy, you would only have to update the object once, and it will automatically apply to all relevant datasets. So, if a new APAC team is added, you just add it to the same security policy definition with a few clicks, and you’re done.
Read more about configuring Security Policies in Satori.
The last step is to select which security policies should be applied to our dataset. In the dataset security policy configuration tab, select one or more policies, and Satori will take care of the rest. In the screenshot below, we chose to add the above Regional Access policy. You can apply the same policy to any number of datasets. In the case of a change to an existing policy, you would only have to update the object once, and it will automatically apply to all relevant datasets. So, if a new APAC team is added, you just add it to the same security policy definition with a few clicks, and you’re done.
 That concludes the required configuration, and, from now on, US and EU users who access regional data across all data locations will only see records relevant for their region.
That concludes the required configuration, and, from now on, US and EU users who access regional data across all data locations will only see records relevant for their region.


