"A couple of weeks ago, I wrote a guide about implementing row-level security in Snowflake, and today I will do the same for column-level security. We’ll cover the following topics:
Column-level security is also known as column-based security, or column-based access control. Like its sibling, row-level security, it allows you to set fine-grained access control within a table object in a database. While row-level security filters the records you can view according to your role or access level, column-level security sets the type of data you have access to, or in other words, which columns can you access. The examples in this article will focus on read access, but the same method can be applied to other operations, such as data updates or insertion.
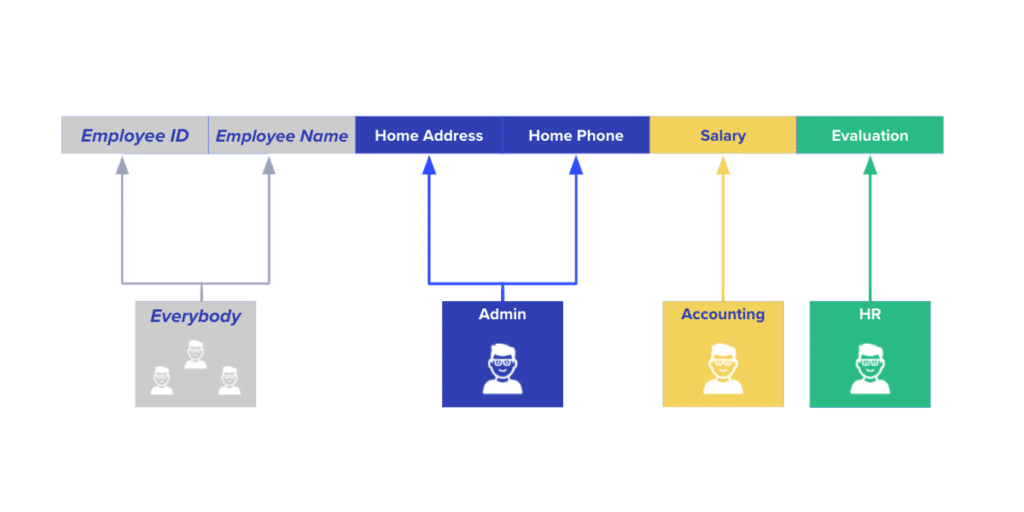
Why would you allow users to access some table columns while restricting their access to others? Let’s consider a table that contains extensive data on each employee in ACME corp. Some of the columns are only visible to accounting, because they contain specific financial data. Others are only visible to HR and managers, as they contain evaluation rankings, and some are only visible administrative employees, who send bouquets of flowers to the employees every weekend to boost morale (don’t all companies do that?).
The structure may look something like this:
Needless to say, this is a simplified example. In practice, there are many more columns, groups, and overlaps. For example, in many organizations, HR also has access to salary information, but accounting is not able to view employee evaluations. These complications are outside the scope of this blog post, however, as our focus is on column-based security.
An alternative to column-based security is splitting the data across different tables, and then allowing employees access to different levels of data with or without a key, such as an employee ID. This will work in many cases, but in others, it will create complications when we try to access employee data. These possible complications include when several teams need similar access, which may lead to either over-privileged access, or to duplication of data, bringing you one step closer to data mayhem.
In other words, column-based security, like many other access control methods, is not a must for all architectures and types of data, but it is definitely not something that you should be afraid of, as it serves an important purpose.
Explicit vs. Implicit Column-Level Security
As with row-level security, column-based security can also be implemented in an implicit or explicit way. When implementing it implicitly, users who query data they don’t have access to will simply see empty columns. With explicit access control, the user will only be able to query the columns they have access to.
The benefit of enforcing implicit access control is that users will encounter fewer errors. If they try to access data they don’t have access to, it will simply be empty, or masked. The downside, however, is that errors may occur, as these data consumers don’t know if the columns are empty because they do not contain values, or because the user has insufficient permissions.
Three Ways to Achieve Column-Based Security
There are three main ways to set up column-based security in databases:
In certain databases, columns are securable objects. That means you can grant and revoke access to columns for certain users or roles just like you do with tables. An example would be setting up column-based security in Redshift. In Snowflake, however, columns are not securable objects, and you can’t use GRANT or REVOKE commands on a column.
A popular way to grant granular access control is by using a View, an abstract layer that the user accesses rather than accessing the table directly. The View contains filtering of the returned result set from the query, according to certain conditions (such as the querying user or role).
The third way to set up column-based security is by using masking policies to set dynamic masking, which will modify the data as it’s being pulled from the database.
Column-Level Security in Snowflake
You can implement column-based security in Snowflake in two different ways. The first is by using a Secure View to abstract data from the underlying table, and the second is by using the Dynamic Masking feature. Note that Dynamic Masking is currently only available to Enterprise accounts or higher.
Column-level security using Secure Views
We will first use Secure Views to create an abstract layer with conditions using the SELECT CASE command. Let’s start by creating a test table with the three roles mentioned above, and populating our table with a sample row:
Now that we have the data, let’s create the Secure View. As noted, this is an example, and implementing it may differ greatly as there may be overlapping roles or other variables:
CREATE SECURE VIEW v_employees ASSELECT employee_id, employee_name,/* Administration specific columns: */CASEWHEN current_role() in ('OFFICEADMIN') THEN home_addressELSE''endAS home_address,CASEWHEN current_role() in ('OFFICEADMIN') THEN home_phoneELSE''endAS home_phone,/* Accounting specific columns: */CASEWHEN current_role() in ('ACCOUNTING') THEN salaryELSE0endAS salary,/* HR specific columns: */CASEWHEN current_role() in ('HR') THEN evaluationELSE0endAS evaluationFROM employees_table;
Now that we have created the abstract view, let’s test it by granting the different roles privileges to select data from the view (don’t forget to also grant your user these roles), and examine the different results we get for the same query:
GRANTSELECTON v_employees TO OFFICEADMIN;GRANTSELECTON v_employees TO ACCOUNTING;GRANTSELECTON v_employees TO HR;USEROLE OFFICEADMIN;SELECT * FROM v_employees; /* We should get only common fields, address and phone */USEROLE ACCOUNTING;SELECT * FROM v_employees; /* We should get only common fields and salary */USEROLE HR;SELECT * FROM v_employees; /* We should get only common fields and evaluation */
As things complicate, we may use the same trick we introduced for row-based security, using all of the available roles instead of just the current role, joining with tables containing permissions, or adding logic via functions. The best method depends entirely on our use-cases. It is also common to create scripts, which will automatically generate these Views.
Now that we have covered Views, let’s go over Dynamic Masking.
Column-level security using Dynamic Masking
Another way to achieve column-level security is by using Dynamic Masking policies, which allow us to define the masking rules that will be applied to data access. We define the transformation for the different data fields according to the different roles, and then we assign them to our different columns.
Let’s first define the masking policies:
CREATE MASKING POLICY emp_contact AS (val string) RETURNSstring ->CASEWHEN CURRENT_ROLE() IN ('OFFICEADMIN') THEN valELSE''END;CREATE MASKING POLICY emp_financial AS (val integer) RETURNSinteger ->CASEWHEN CURRENT_ROLE() IN ('ACCOUNTING') THEN valELSE0END;CREATE MASKING POLICY emp_hr AS (val integer) RETURNSinteger ->CASEWHEN CURRENT_ROLE() IN ('HR') THEN valELSE0END;
Note: If you receive an Unsupported feature 'MASKING POLICY <YOURACCOUNT>’ error, that means that your account is not Enterprise or above, and you can’t use Dynamic Masking until you upgrade your account.
Now, let’s assign the policies accordingly. You will notice that it is easier to reuse Dynamic Masking policies than to create views per table. It feels more like configuration and less like scripting:
ALTERTABLE employees_table MODIFYCOLUMN home_address SET MASKING POLICY emp_contact;ALTERTABLE employees_table MODIFYCOLUMN home_phone SET MASKING POLICY emp_contact;ALTERTABLE employees_table MODIFYCOLUMN salary SET MASKING POLICY emp_financial;ALTERTABLE employees_table MODIFYCOLUMN evaluation SET MASKING POLICY emp_hr;
Now, when we grant SELECT to the different roles in the employees_table (this time we’re giving access directly to the securable object), we will get the data per our role.
Caveats & Limitations
Snowflake gives you a good toolbox to set column-level security. However, it does have its limitations, including:
Managing access can be tricky, especially at large scales or when there are complications like overlapping roles or combinations of row and column-based security.
Creating and maintaining those views takes time. In certain cases, it transforms access control into a Spaghetti code that only one or two daring data engineers are brave enough to actually touch in production, especially when complicated changes are required.
Secure views reduce data read optimizations and hinder performance.
All changes are written inside the data store, and if you’re using several different technologies, you need to implement the same business logic in different technologies, which may create complications.
Someone needs to define views or policies per securable object, meaning they need to understand the data and security aspects (such as whom the data stewards are, and who needs which granular access). This may be a lengthy process, and it may cause problems, such as increased risks or impact on business.
Column-level Security in Satori versus Snowflake
When we envisioned building column-level security in Satori on top of data stores such as Snowflake, we wanted to make life simpler for data and security teams so they can focus on their core business goals rather than on mundane operations. That is why we chose to deliver universal security policies decoupled from the data infrastructure itself.
Universal masking column-based security policies can be as simple as:
Security policies can be applied on specific columns, and also on column groups and columns from different tables simultaneously to streamline policy creation, and make it more robust and easier to understand and maintain.
Satori access policies are universal. This means that you can set access policies in a logical way and apply them to different data stores in the exact same way.
In addition, Satori automatically discovers data types and enriches data access with context. That means that instead of tracking all data types (like PII, phones, IP addresses, etc.) and setting specific policies for them, we can assign the policies directly for those data types.
If you’d like to learn more about how we can help you spend less time on security, privacy and compliance, and more time on data engineering and analytics, contact us.
"
Ben is an experienced tech leader and book author with a background in endpoint security, analytics, and application & data security. Ben filled roles such as the CTO of Cynet, and Director of Threat Research at Imperva. Ben is the Chief Scientist for Satori, the DataSecOps platform.


 Needless to say, this is a simplified example. In practice, there are many more columns, groups, and overlaps. For example, in many organizations, HR also has access to salary information, but accounting is not able to view employee evaluations. These complications are outside the scope of this blog post, however, as our focus is on column-based security.
An alternative to column-based security is splitting the data across different tables, and then allowing employees access to different levels of data with or without a key, such as an employee ID. This will work in many cases, but in others, it will create complications when we try to access employee data. These possible complications include when several teams need similar access, which may lead to either over-privileged access, or to duplication of data, bringing you one step closer to data mayhem.
In other words, column-based security, like many other access control methods, is not a must for all architectures and types of data, but it is definitely not something that you should be afraid of, as it serves an important purpose.
Needless to say, this is a simplified example. In practice, there are many more columns, groups, and overlaps. For example, in many organizations, HR also has access to salary information, but accounting is not able to view employee evaluations. These complications are outside the scope of this blog post, however, as our focus is on column-based security.
An alternative to column-based security is splitting the data across different tables, and then allowing employees access to different levels of data with or without a key, such as an employee ID. This will work in many cases, but in others, it will create complications when we try to access employee data. These possible complications include when several teams need similar access, which may lead to either over-privileged access, or to duplication of data, bringing you one step closer to data mayhem.
In other words, column-based security, like many other access control methods, is not a must for all architectures and types of data, but it is definitely not something that you should be afraid of, as it serves an important purpose.
 Needless to say, this is a simplified example. In practice, there are many more columns, groups, and overlaps. For example, in many organizations, HR also has access to salary information, but accounting is not able to view employee evaluations. These complications are outside the scope of this blog post, however, as our focus is on column-based security.
An alternative to column-based security is splitting the data across different tables, and then allowing employees access to different levels of data with or without a key, such as an employee ID. This will work in many cases, but in others, it will create complications when we try to access employee data. These possible complications include when several teams need similar access, which may lead to either over-privileged access, or to duplication of data, bringing you one step closer to data mayhem.
In other words, column-based security, like many other access control methods, is not a must for all architectures and types of data, but it is definitely not something that you should be afraid of, as it serves an important purpose.
Needless to say, this is a simplified example. In practice, there are many more columns, groups, and overlaps. For example, in many organizations, HR also has access to salary information, but accounting is not able to view employee evaluations. These complications are outside the scope of this blog post, however, as our focus is on column-based security.
An alternative to column-based security is splitting the data across different tables, and then allowing employees access to different levels of data with or without a key, such as an employee ID. This will work in many cases, but in others, it will create complications when we try to access employee data. These possible complications include when several teams need similar access, which may lead to either over-privileged access, or to duplication of data, bringing you one step closer to data mayhem.
In other words, column-based security, like many other access control methods, is not a must for all architectures and types of data, but it is definitely not something that you should be afraid of, as it serves an important purpose.


