In the past, we have been involved in data projects which required meeting geographic-specific requirements. These requirements primarily pertained to where the data is stored and limiting who can access data. Though the specifics of each case vary, there is a set of common problems that Satori helps simplify.
Meeting data localization requirements in a cloud data platform with users that often connect from different locations can be challenging. Knowing where your data is stored is easy (as you are setting the data location), but meeting requirements surrounding the location of data users can be more challenging. These complexities are multiplied when the requirements themselves are more granular (e.g., applying data masking based on the origin country of the user).
This article will discuss some of the reasons and use-cases for applying “data geo-fencing” (borrowing the term from this great Snowflake webinar). We will learn how Satori can simplify creation of such policies.
Why Control Data Access Based on Regions?
There are several reasons to apply data access restrictions based on the user’s origin. One of these reasons is meeting compliance requirements such as stipulating that users from that country or region can only access users’ data from a specific country or region.
Another reason can be meeting security requirements. Limiting access to a particular geographical area can mitigate risk. The company’s employees should only access the data store (e.g., database, data warehouse, or data lake) from certain countries.
A third reason is meeting contractual obligations. For example, sometimes specific customers demand geographical restrictions over access to their data.
Common Requirements of Data Access Locations
These are some of the standard requirements that we see when controlling access based on geographical location:
Visibility: Logging & Monitoring
In some cases, companies need to be able to answer questions continuously, such as:
- From where are my data users coming?
- From which countries are users accessing which datasets?
- From which countries do users access sensitive data (such as PII)?
The answers to these questions can be used for monitoring or for compliance reporting.
Access Restrictions Based on Location
Another use case is wanting to block access to data based on a location. These restrictions can be in the form of complete blocking to a data store or blocking access to specific datasets (e.g., preventing access to certain tables unless a user is from a particular location).
Differential Privacy Controls Based on Location
Similar to the above situation, some companies want to mask specific data types unless the data consumer is from a particular location. For example, companies can define controls such that users from Germany will be able to view PII as clear text, but external users will get masked values.
Knowing Users’ Origins
There are several ways to find out where the user comes from. Their location can be taken from the IdP (Identity Provider), it can be found based on the IP address from which the user is connected, or it can even be a combination of both conditions. A company’s optimal stategy depends on its specific requirements, architecture, and available data.
Challenges in Native Data Store Capabilities
In many cases, meeting such requirements by using native data store capabilities can be challenging, and doing so may require your data engineering team to execute a fully-blown cross-team high-resource data project. A few examples we’ve seen are:
- Adding post-processing on audit logs to include IP location information in data access audits.
- Making changes in identity management, reflected in RBAC authorization, such as specific identity groups, to “tag” people per requirements, and then add checks for such groups in database views.
- Data duplication according to different regional requirements.
- Dynamic views joined with an “IP to location” table (with a performance impact).
Using Satori to Simplify Regional Data Access
As a universal data access platform, Satori simplifies solving regional data access challenges in the following ways:
Visibility of Geolocation
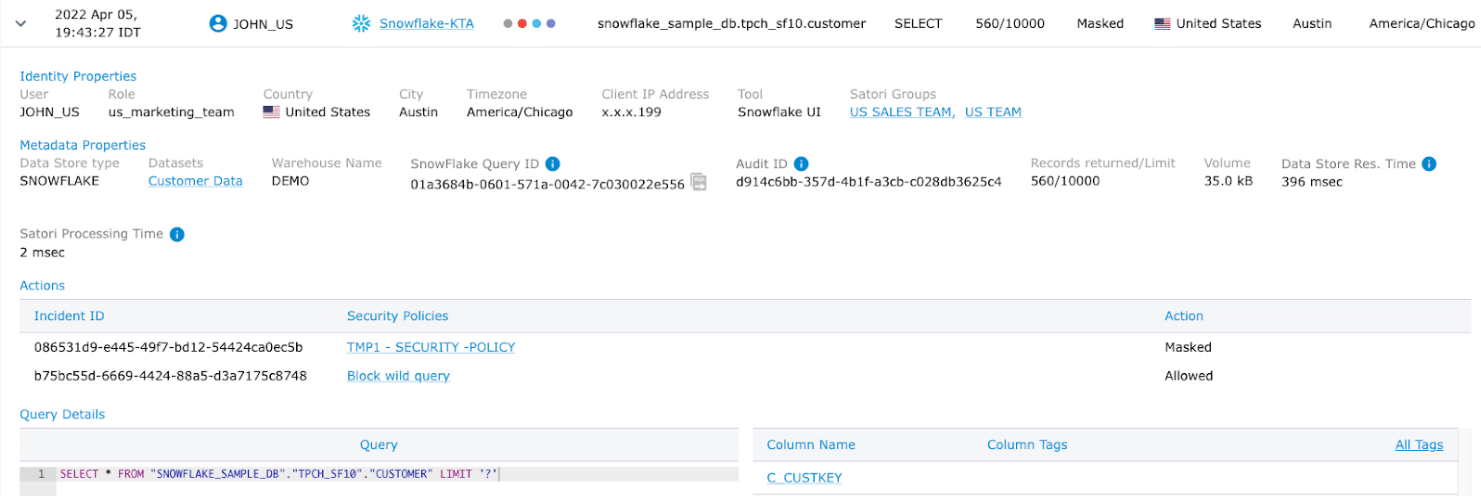
In many cases, the simple requirement of knowing the locations of our data consumers is difficult to satisfy. It may require some ETLs performed on access logs to have the reporting required. With Satori, the IP geolocation information is available directly from the audit log, so you can create reports based on the location of users and export the data access audit log to other systems (such as your security data lake).
As you can see in the screenshot below, for each data access request, you receive a lot of information, including the type of data accessed, the identity of the user (even if the user is using a BI tool), and part of the data is also the user’s location:
Setting Security Policies According to Region (Based on IP Address)
In Satori, you can set regional access policies either based on identity groups (e.g., “analysts_eu”) or on IP origin. For example, you can set a custom policy such as the following to block access to a specific dataset from non-European IP addresses:
- name: Block access from non-eu IPs
action: block
priority: 0
data_tags:
- not client.continent.code::EU
In the same way, you can define policies with other geolocation tags:
- IP Addresses
- Countries
- Cities
- Time Zones
For a complete reference to the geolocation tags, visit our geolocation tags documentation page.
Setting Security Policies According to Region (Based on Identity Provider)
Security policies can also be implemented by using data from your identity provider (IdP). For example, we gave access to a dataset to the “euteam” identity group as shown below:

Datasets can be tables, databases, or even data across multiple data platforms (e.g., Snowflake, Redshift, Postgres, and more). Such a capability makes it very simple to manage data localization projects at scale with Satori. In addition, you can integrate Satori with your data operations using our REST API or our Terraform provider.
Further, security policies can include fine-grained access control. Granular access may mean that, based on your region, you will only be able to view certain records in a table (i.e., row-level security). Granular access can also mean that you want users to be able to only access specific types of data in a masked or redacted way (i.e., dynamically masked).
Takeaways
Applying security policies that allow you to apply “data geo-fencing” or meet data localization requirements can be complex, time-consuming, and error-prone. By using Satori, you can simplify this process. If you want to learn more about how Satori can help meet your specific needs, we would be happy to set up a 1:1 meeting, or, if you would like to try out Satori, you can get a test-drive account up and running in only a couple of minutes.