

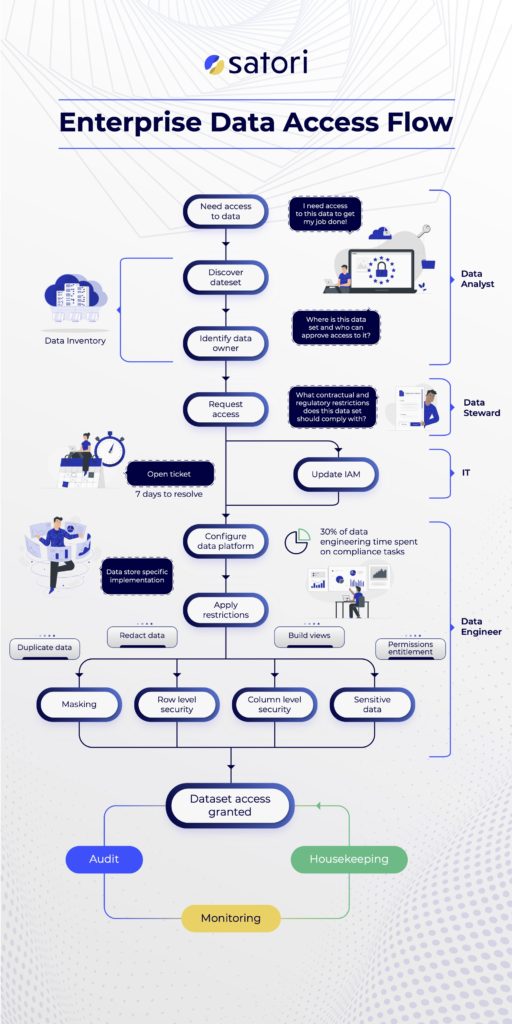
Let’s understand the chain of events that leads to data access. For example, imagine you have an online travel booking platform, and one of the data science teams wants to see if predictions about the users (which come from usage and enriched data) will affect the success of promoting boathouse trip packages so your company can better target those users.
For simplicity’s sake, I will assume that the company’s entire data is stored in Snowflake’s data cloud. In real life, parts of the data may be stored in different data platforms, which creates additional complexities.
There are many flavors of access control management in Snowflake, and in this post I’d like to explain why gaining access to data, which is a prerequisite for extracting value, is tough, especially at scale. I will follow the path from a data consumer’s perspective and examine some different approaches for data access in Snowflake.
We will walk through the following data path:
- Discovering the Data
- Accessing the Data
- Fine-Grained Access Control
- Snowflake Role Auditing & Monitoring
Discovering the Data
In our imaginary travel booking service, the data science team leader, Alex, needs to know where he can pull useful data from. “Useful data” can be enriched data from external sources about users in the system, as well as order history, search history and more. How does Alex know where to find this data? He may find it in the organization’s data catalog or data inventory, if it has one.
In most organizations, relying solely on a catalog would be very optimistic of Alex, as it is rarely up-to-date, or it’s incomplete, if it exists at all. In the real world, Alex will probably need to ask around to learn what data he can work with, which he will follow by initiating a manual access request workflow through the enterprise’s ticketing system (i.e. ServiceNow and similar systems).]
Accessing the Data
Alex now knows what data he can work with, but that doesn’t mean he has access to it or can start playing with it. Depending on his organization’s metadata maturity, it may be simple or difficult to find the data owners, who need to authorize his access.
For this example, let’s assume that the organization has Snowflake integrated with Okta to set users and roles (Snowflake roles are a representation of the Okta groups). Now, assuming that the data is in Snowflake and that Alex does not have access to the data, there are several ways in which Alex can gain privilege to read the data. I explained these methods when I wrote about Snowflake roles management at scale. Here’s the summary:
| Method | Pros | Cons |
| IAM groups | Minimal Snowflake roles | Dependency on IT. Requires data access modeling in the IAM. |
| Permissions | Central management | Data stewards can’t assign permissions. Create overhead for data engineering. |
| Role Hierarchy | No changes to per-role securable object privileges | May lead to “Hierarchy Hell” (complex roles relations) |
| Role per User | Granular | High-Maintenance |
| Open Access | No interruption to data consumers | Security & compliance risks |
| Self-service data portal | Lightweight for data consumers and data engineering | Requires homegrown development & application maintenance |
Fine-Grained Access Control
Even within the data sets to which Alex gained access, additional data access restrictions will apply in many cases. Note that the restrictions are not alternative, and many organizations require more than one of these fine-grained access controls (for example, column-level security in addition to row-level security). The granular restrictions include:
Column-Level Security
Column-level security (or column-based access control) enables you to set fine-grained access control, which limits access to certain columns for certain roles (or applies other restrictions based on connection methods, client application used, etc). This allows you to select a specific subset of the users to access certain sensitive data. If you’d like to learn more about this, read our Snowflake column-level security guide, complete with code examples.
Row-Based Security
Row-based security (or row-based access control) enables you to set fine-grained access control, which limits access to certain rows for certain roles (or applies other restrictions based on connecting methods, client application used, etc). This allows you to enable certain teams to only see data records relevant to them. For example, in many financial organizations, analysts are only able to view data for certain accounts. If you’d like to learn more about this, read our Snowflake row-level security guide, complete with code examples.
Restricting Access to Sensitive Data
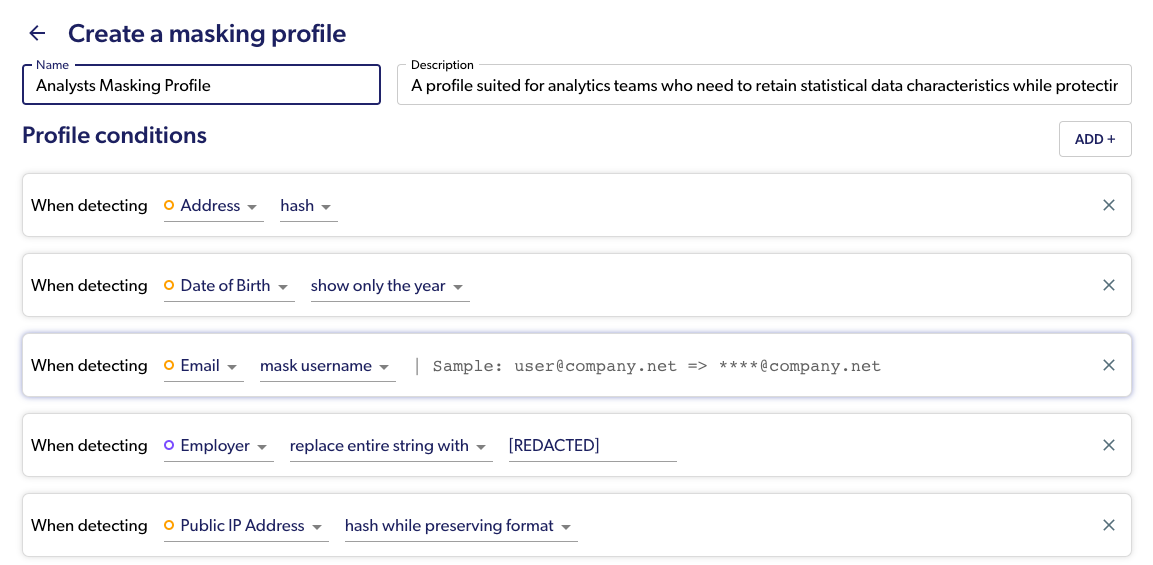
Many organizations require a “blanket” restriction of access to sensitive data, or at minimum, alerts when sensitive data is being accessed. This means that instead of, or in addition to, limiting certain columns, the organization controls all access to specific types of PII, PHI, PCI and other sensitive data. This can be achieved in Snowflake quite easily when integrated with Satori’s universal masking feature:
Restricting Data Access Patterns
I’ve seen a lot of “garden variety” data access restrictions. These may restrict access using certain client applications for certain tools (for example, to make sure analysts are only accessing data using certain BI tools to reduce the possibility of errors or breaches). The restrictions may be on access from certain networks to certain data. Many of these restrictions are for operational reasons, aimed at restricting usage of certain virtual data warehouses by certain roles or over certain data to better control costs; setting other usage limitations based on costs; or even restricting certain queries, which either return too much information or are otherwise unwanted.
Snowflake Role Auditing & Monitoring
At a certain point, Alex will no longer need the data. The project is over, and he now needs different data to complete his next project. In most cases, and partly because gaining access to the data takes time and effort, he will not bother to revoke his access to the data (and neither will anyone else, including the data owner).
Therefore, it is important to monitor data access, audit it, and perform housekeeping on a regular basis to ensure that users don’t have access to sensitive data they only needed for one project a week or more in the past..
Summary
If we look at this process and consider the factors that make data authorization so complicated, we come up with the following reasons:
- Setting up roles and authorizing users to data is complicated because, on one hand, the process has to satisfy many needs, including security, privacy and compliance. On the other hand, it also has to fulfill the needs of data consumers who want quick and easy access to the data.
- Data access management is part of the data infrastructure, and changes are usually made by data engineering teams who are not the data owners, and in many cases do not know the data’s business context. The data owners, on the other hand, do not have the management capabilities to manage the data within the data store (in this case, Snowflake).
- This makes the process inherently complicated, and data engineers become the enforcers of data access, as they’re the ones actually granting access in most cases. Therefore, the process is less efficient, lengthier and more error-prone.
- The model is tied strictly to the data store technology itself, which may create additional friction when the organization has several data storage technologies (which is common).
- IAM, where identity context is usually stored, is owned by a different team than the one managing the Snowflake data warehouse, and the identity context includes a lot of noise (information that’s irrelevant to the data authorization process).


