AI/ML applications are growing in popularity and necessity for organizations. Organizations are looking to become AI ready, expand their operations and leverage their data using AI/ML algorithms to gain a competitive advantage.
To make the most of AI/ML applications that create and tweak data to drive business decisions organizations must collect and store large volumes of data. This data is collected and stored within data lakes and often contains sensitive information that is subject to compliance requirements.
Data can take many different formats from structured and unstructured. All of these characteristics make it difficult to locate and secure it within the data lake. The sheer volume of data required to first develop and then amend AI/ML applications lends itself to risky data management.
This leaves data teams with a dilemma. They want to support the development and evolution of AI/ML applications, however, they need to ensure that all sensitive data is secured.
Securing Sensitive Data
The first step to securing data is locating the sensitive data. The raw data is often stored in data lakes. It is necessary to ensure that all sensitive data within these vast data lakes is discovered and secured. Given the diverse nature of the raw data and the different data stores themselves; data teams can struggle to locate and secure this data quickly.
The second step is to grant access to the data. AI/ML developers require quick access to data so they can provide the most relevant information to the algorithm and also modify existing AI algorithms with relevant feedback. To generate the greatest value from AI applications they need current data.
—–
Example: Prompt Engineering
In ACME, there are prompt engineers who require quick access to data so that they can fix or fine tune prompts for a GenAI algorithm. They need temporary access to data in a controlled way, ensuring the company is not incurring security and compliance risks.
—–
Enabling the right data for writing and maintaining algorithms and models requires fine-grained just-in-time data access controls. While data engineering teams can grant secure data access, this can be a time consuming process for the data teams as they have to locate the data, then implement access controls separately across multiple data stores, and ensure that the level of access accurately applies to the characteristics of the user. After granting access to the data, the data teams also need to ensure that access is revoked at the end of the specified time.
The application of security policies to ensure that the organization remains compliant is time consuming and reduces the productivity of the data teams. Simultaneously, the AI/ML developers require access to data as quickly as possible to ensure that their AI/ML algorithms are up-to-date.
Satori’s Data Security Platform
Satori’s Data Security Platform solves this problem for data teams reducing the amount of time they need to spend on securing data while enhancing their ability to quickly share data with AI engineers. Through automated data discovery and classification, data teams can significantly reduce the amount of time that they spend on locating and securing sensitive data. Fine-grained data access controls allow data teams to set security policies once.
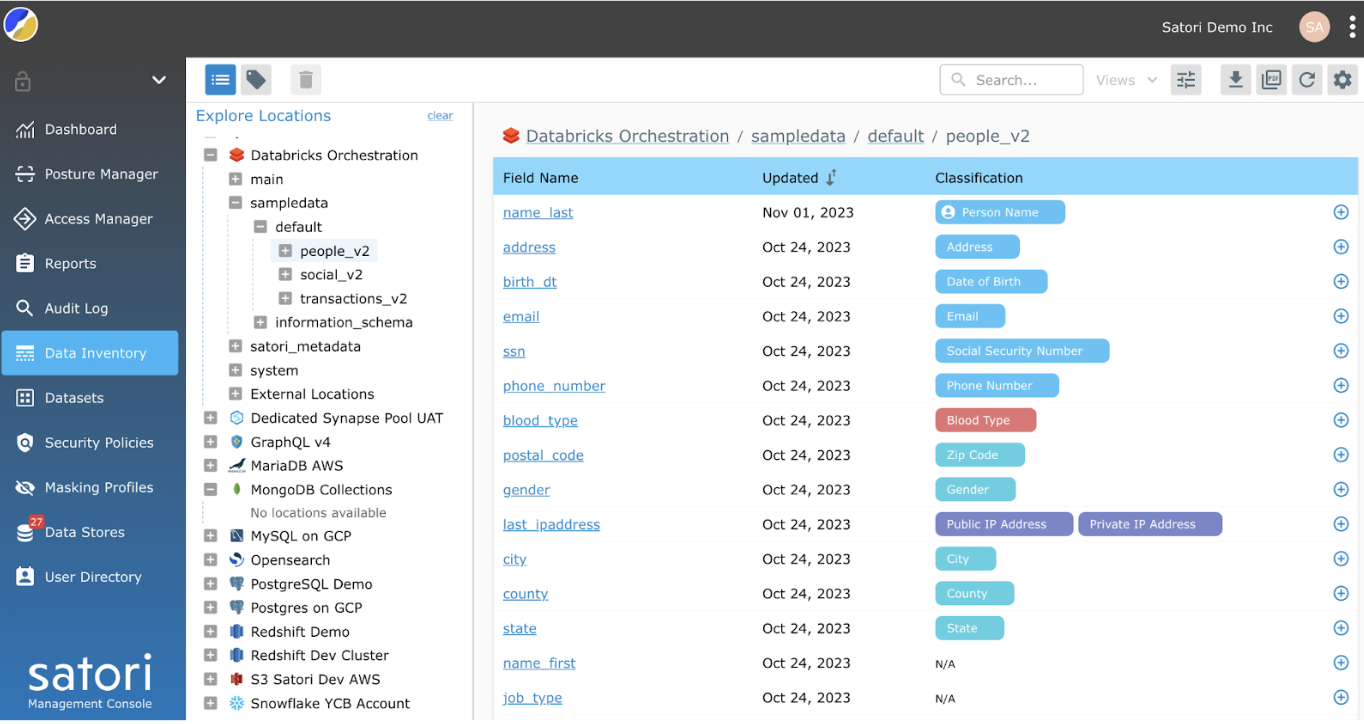
Data Discovery
Data is often spread across data lakes, data warehouses and databases. Satori continuously discovers and classifies sensitive data. The ability to quickly and easily discover and classify sensitive data ensures that sensitive data is tagged and governed properly.
Satori enables data teams to locate sensitive data quickly and easily in various formats, reducing the need to spend large amounts of time on data discovery and classification. Instead, data teams can focus on those areas where they are most productive.
Data teams can use predefined classifiers or create custom classifiers. Once classified, the sensitive data is then masked according to the defined security policies. It is now secured and ready to be appropriately shared with the developers.
Having pre-defined and automatic scanning of data lakes ensures that these steps occur almost instantaneously so that there is no delayed latency from the data. Further, the ability to do this once and have it applied across disparate systems significantly reduces the time that data teams need to spend on this step.
Secure Data Access
Granting quick access to data stored in data lakes is a critical component in developing AI/ML models and their on-going handling. Organizations that can leverage their data securely have a step up in the race to develop more accurate AI/ML algorithms.
Security policies are designed to protect sensitive data and fall under the regulations outlined in GDPR and CCPA for the use and sharing of sensitive data. The more secure sensitive data is, the less likely that a security breach, which costs USD 4.45 million on average, occurs. The ability to reduce the risk associated with sharing of sensitive data, and doing so quickly, is not trivial.
Satori’s fine-grained just-in-time data access provides data teams with the tools to grant data access quickly and securely. The data teams can apply predefined masking rules and security policies across all data stores according to user definitions. Satori provides both self-service data access and just-in-time data access.
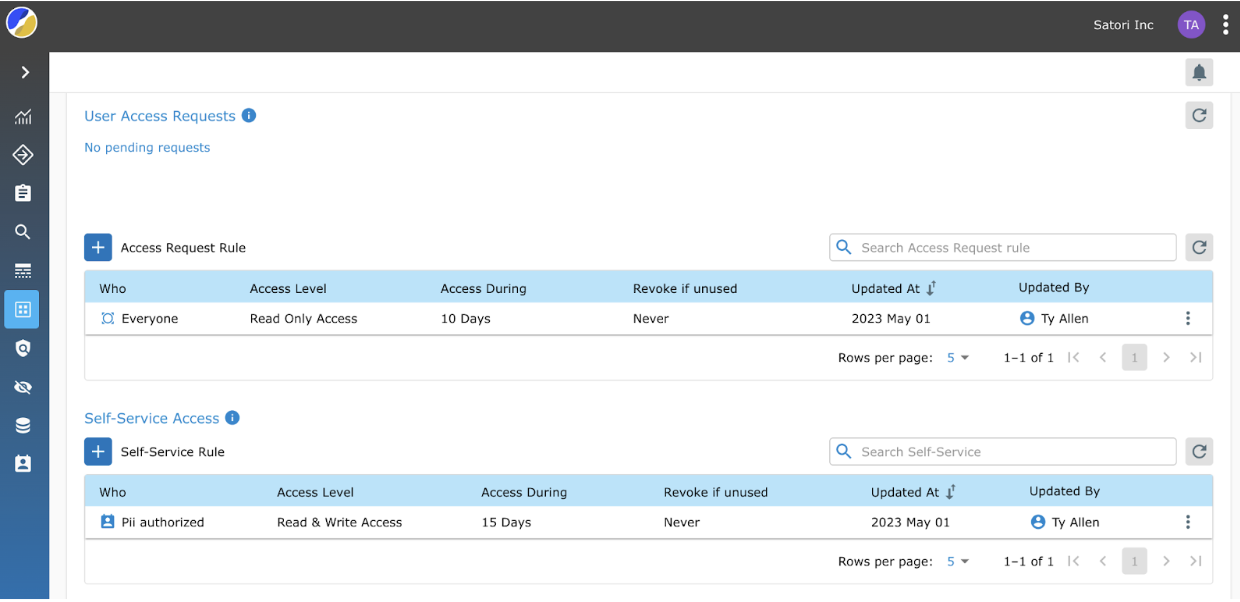
Self-Service Data Access
Predefined rules are applied based on users’ identities. The access rules and security policies redact the necessary information. The data set is then immediately available in the user’s personal data portal.
This data is available for a specified period of time after which the data is removed from the user’s personal data portal.
The ability to grant access on a self-service basis ensures that data moves quickly and securely to AI/ML developers. Additionally, the ability to set up security policies once and not many times across multiple stores free up data teams’ time and resources.
Just-in-Time Data Access
Satori’s fine-grained security controls provide just-in-time access to users without burdening data teams with multiple manual access ticket requests. In this case, if the data that the developer needs is not within their data portal, they can request access from the system administrator.
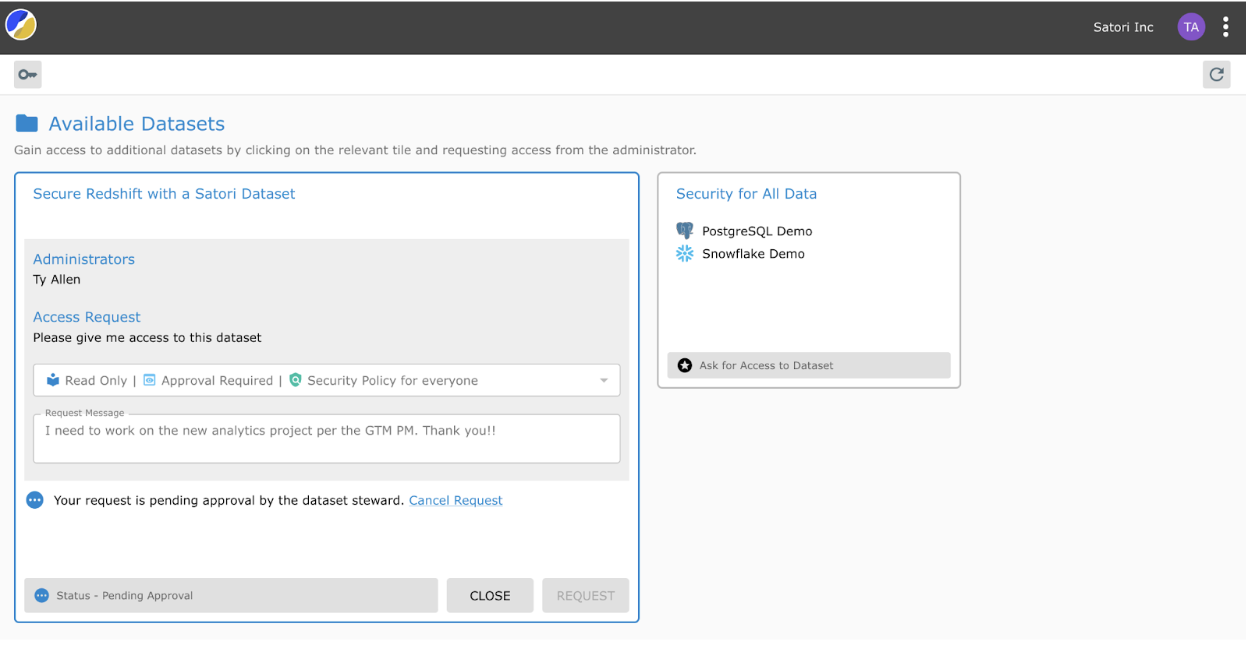
The system administrator then either grants immediate access with the applicable security policies applied based on the user’s role or attribute; or access is denied.
The ability to set security policies once and have them applied across multiple data stores and user roles/attributes reduces the strain on data teams and ensures that data moves quickly to developers.
Compliance
It is necessary to discuss the security and compliance aspects of secure data sharing for AI/ML applications. While sensitive data is strictly covered in GDPR and CCPA regulations, these are evolving quickly to match the pace of AI/ML development. As new developments occur, security and compliance must also evolve to protect individuals.
Satori’s cross-cloud and cross data platform audit logs and UDPS (Universal Data Permissions Scanner) mean that data teams always know who has access to what data, why they accessed it, and for how long. The ability to have this information almost instantaneously significantly reduces the burden on data teams, who must ensure that all compliance requirements are met and then implement any changes to compliance requirements.
Conclusion
The explosion of AI/ML applications has led to organizations developing large data lakes. However, data teams are often tasked with ensuring the security of sensitive data within these data lakes. This is a time consuming project that seemingly has no end in sight.
However, Satori’s Data Security Platform automatically scans all data to discover and classify any sensitive data within the data lake. Then with the ability to set security policies once and have them apply by user characteristics across multiple data stores reduces the burden to grant manual access. Now data teams are happy to have AI/ML developers instead of being burdened with their frequent access requests.
To learn more about data teams can take back their time with while enhancing the development of AI/ML applications, book a demo with one of our experts.