

In this article, I will discuss how people perform data classification using Satori and explain why Satori is a great choice for you to manage all of your stored data types. Before we dive in, here is a quick summary video:
One of the core principles of DataSecOps is prioritizing knowledge about the location of your sensitive data and then prioritizing resources for security and governance of that data. Another guiding principle is that continuous processes are always preferable over ad-hoc projects because data changes very often. Specifically, sensitive information tends to show up in unexpected places, and you do not want to face a Murphy’s law situation of having sensitive data appear in a new location right after you finished mapping your sensitive data.
As we have learned in our previous guides to data classification, it is important to understand the reasoning behind a data classification project. In most modern data environments, where data is moving and changing quickly, a primary reason behind data classification is that it is important to continuously scan the data for sensitive data.
Continuous Sensitive Data Discovery in Satori
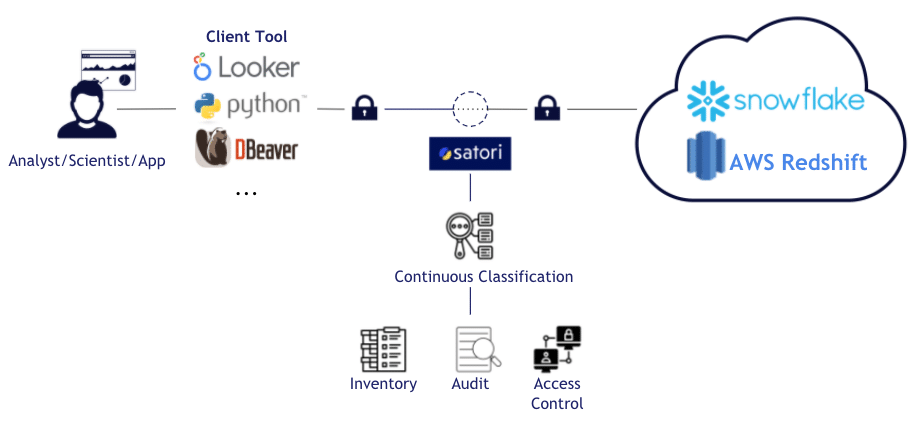
This is where Satori comes in. At Satori, it was extremely important for us to design our product so that it continuously scans data as it is being accessed in real time. Let’s start by reviewing the flow of what is happening (with regards to data classification) when you use Satori:

As you can see in the chart above, when your users are going through Satori, it continuously analyzes the data that is sent by the users (i.e. queries or commands) as well as the data that is returned from the data stores (e.g. Snowflake, Redshift, or others) back to the user. If needed, Satori also applies other capabilities such as self-service access control. In addition to these extra capabilities, Satori scans the data which passes through to classify specific data types.
The main categories of data which Satori scans for are:
- PII (personally identifiable information), such as person names, addresses, phone numbers, etc.
- PCI (payment card industry), such as credit card numbers.
- Operational sensitive data, such as passwords or financial information.
- PHI (protected health information), such as patient identifiers and healthcare data.
You can find our complete list of classification tags here.
The classified data can then be used with Satori to perform important functions. The main uses for the classified data are described below:
Data Inventory
Satori automatically updates the data types found in its inventory which provides you with up-to-date information about the locations and types of sensitive data in your organization.
In the screenshot below, you can see the Data Inventory that is generated automatically by Satori as data is being accessed:

Data Access Audit
Satori displays the types of data that are being accessed in its data access audit, allowing you to view what types of data were being accessed in each log entry. You can then create reports based on this information and investigate users’ access to sensitive data.
In the screenshot below, you can see an audit entry which contains the data classified:

Access Control & Security Policies
Satori allows you to use the classified data types in security policies and access control configuration. For example, in addition to being able to set security policies for known locations, you can set them directly based on data types. For example, even for new locations where PII is discovered, it will automatically be masked from that point forward.
In the screenshot below, you can see a Satori dynamic masking definition, based on data types classified:

Semi-Structured Data Classification
Semi-structured data is often either overlooked or classified uniformly as one chunk in many data classifications (e.g. a message containing 1,000 different values will be marked as ‘email’ solely because one of the values is an email address). This problem is further intensified, as semi-structured data is used quite often due to its flexibility and the fact that it requires less overhead when loading it into your favorite data store.
A data classification tool that does not fully support the classification of semi-structured data can have negative effects both on audits and on reducing sensitive data leakage. Also, because semi-structured data is inconsistent in many cases, it is important to classify it continuously. For example, semi-structured data may contain additional keys that are added over time, without any database schema change.
In Satori, we regularly handle data in warehouses and lakes which utilize semi-structured data, so it was important for us to ensure that we also correctly classify data within semi-structured data. When Satori scans data and encounters semi-structured data, it automatically saves and adds to the data inventory locations where classified data was discovered within the semi-structured data.
Overriding Satori’s Classifications
At Satori, we have designed our data classification system to be the most suitable for your data. This means that with Satori, you can also easily override any classifications. You can add specific classifications to locations (and you can even use our API to automate this process from other platforms you use), or you can remove classifications for irrelevant locations.
How Sensitive Data Is Discovered by Satori
Satori is a data access controller that does not change anything about the way your data users utilize the data (i.e. no changes in queries or commands) and does not change anything in the data stores themselves (i.e. no views or schemas created, Satori does not even a use a database user). Rather, Satori acts as a proxy between the data users and the data stores, and we only change the host to which the users are connected.
Because Satori is positioned at the point of data access, Satori is able to scan both the queries and the data returned to the users and learn the different data types customers hold. Most of the classification is done by analyzing the data returned from the data store. Classification is done using the following methods, depending on the data type:
Dictionary Matches
For some data types, we use dictionaries or lists of values, most often by incorporating additional logic to the classification. For example, if all “significant” values in a certain location called ‘state’ are US states, it probably means that the location holds specifically US states. However, if ‘state’ returns values such as ‘idle’, ‘ongoing’, and ‘completed’ it will not be classified as ‘US states’ but rather as ‘project states.’
Pattern Matching
Some data types are ideally identified by pattern matching. Some examples of this data include email addresses, which all follow a (somewhat complex) pattern. When classifying other data types, we often use pattern matching as part of the algorithm.
Algorithm Matching
Some data types are discovered by applying certain algorithms. For example, credit card numbers are calculated (as part of the process) by applying the Luhn algorithm, which when used in a statistical manner (as we do), significantly reduces the chances of false-positive matching.
Machine Learning
Some data types are best discovered by extracting certain features and then applying a trained machine learning algorithm to classify the data. An example of such data is loosely patterned data types such as street addresses.
What About Data That Is Not Accessed?
Though we believe that we can extract the most value from discovering sensitive data as it is being scanned, in some cases, our customers want to run a “full scan” on their repositories. In those cases, it is easy to run these full scans by retrieving a sample of data from your data stores.
Conclusion
An important part of what Satori does is continuously classifying data as it is being accessed in real-time. We believe that this is the best way to discover sensitive data for data that may change. If you would like to set up a demo, please fill out this form:


