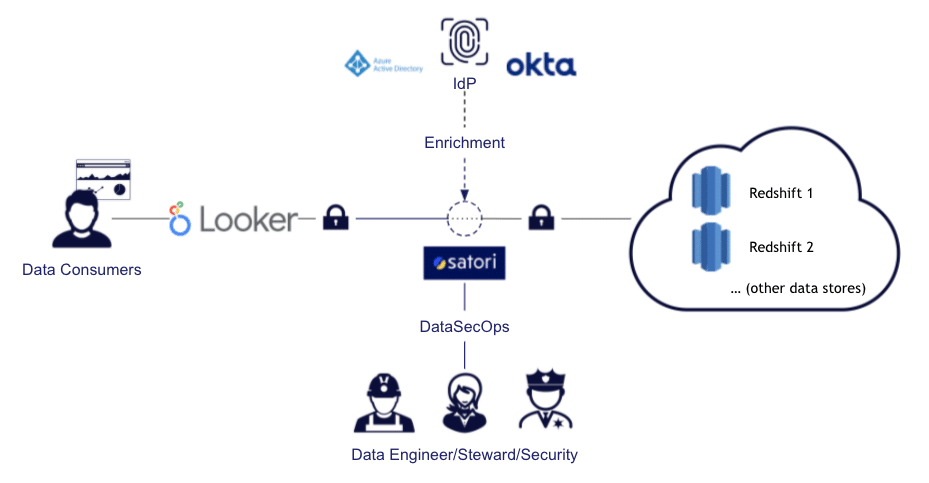
I’m guessing there is no need to introduce you to Amazon Redshift or Google Looker, but let’s do so briefly, for good manners. Looker is a widely-used BI platform, utilized for data discovery, analytics, and reporting. It connects to a wide range of data sources, and one of the important ones it connects to is Amazon Redshift. Amazon Redshift is often an important aspect of an Amazon Lake House Architecture, as it can be used both as a data warehouse and as a query engine for a data lake. It is essentially an implementation of Postgres, running on a cluster that you can manage using your AWS console or API. We have also published a dedicated guide to Redshift Security, in case you would like to deep-dive on that subject.
In this post, I am going to discuss some of the benefits of using a Looker-Redshift-Satori stack to provide you with simple data access as well as better data security, governance, and privacy. When discussing these topics, I am considering an organization with a DataSecOps mindset, meaning that it wants to accelerate access to data (because doing so brings more value) while minimizing security risks.
Here’s what we’ll discuss:
- Looker and Redshift User Management
- Looker Users in Redshift Database Audits
- Looker User Directory Groups for Redshift
- Looker Row-Level Security with Satori for Redshift
- Looker-Redshift Continuous Data Classification with Satori
- Looker-Redshift Policies with Satori
- Learn More

Looker and Redshift User Management
In a typical integration, when Looker is configured to work with a certain AWS Redshift cluster, the configuration is done by creating a Looker user in Redshift (by using the CREATE USER command) and then granting SELECT access to the required tables (using the GRANT command).
While this is a straightforward way to connect Redshift to Looker, there are two main downsides:
- When you are analyzing your Redshift usage, by examining the database logs (read more about Redshift auditing & monitoring here), you will only see queries done by the Looker user, and understanding which specific users (or even teams) performed the queries and what data they retrieved becomes a challenge.
- Data access is blunt within the data infrastructure (which uses a single user), meaning that you need to create an additional data access model and configuration specifically in Looker.
Fortunately, you can solve these issues in a relatively simple way with Satori, as described below.
Looker Users in Redshift Database Audits
When using Satori with Looker, the configuration links the Looker users and utilizes them in Satori. This way, you can have an audit log based on the user using Looker, rather than a generic Looker user, which is very helpful in analytics.
This capability helps fill a gap in both compliance and security, as, otherwise, the database query and access logs only contain the Looker generic user. If, for example, you want to generate a report with all employees who were accessing a specific data type (e.g. PII) or a specific location (e.g. salaries table), you can easily do so using Satori.
Looker User Directory Groups for Redshift
Using Satori, you can define custom user groups for access with Looker to your Redshift data warehouse. In this manner, you can limit access to certain datasets or even allow data access only after going through specific data workflow triggers.
For example, a data owner can decide to allow a certain dataset to be open to a certain group, but only after providing a business justification, and to another group only after obtaining a specific approval. This configuration is made in a straightforward way and is applied in the same manner as data access with other tools. This means that, if, for example, the organization wishes to add another BI tool, it can do so without making specific configuration changes in the different BI tools which may be based on different models.
In the image below, we can see such data access done by a Looker user, which is shown as the analyst himself, not as a generic user:

Looker Row-Level Security with Satori for Redshift
When you want to apply row-level security on Redshift data for users employing Looker, you can do so by using the access_filter parameter in Explore. However, by applying row-level security in Satori, you ensure that users will get the same restrictions throughout all tools (not just Looker) and, if needed, across different data platforms. For example, you could apply row-level security policies to data that is stored in Redshift, but also in Postgres, Snowflake, or other data stores.
Looker-Redshift Continuous Data Classification with Satori
Whenever data is being accessed by Looker users, it is being classified by Satori, and if there is new sensitive data, it is being discovered in real-time. With Satori, you can apply masking policies to desensitize data without configuring specific data locations so that, even if sensitive data (such as PII) is discovered in a new location, it will be masked when retrieved. This configuration can be limited only to Looker, only to certain datasets, or only to specific users.
Looker-Redshift Security Policies with Satori
Using Satori, you can apply security policies to protect the data queried by Looker, which is stored in Redshift, in the same manner as data that is retrieved using other tools and data stores. You can then focus on the business goal - for example, you may want to apply security policies that block access to certain types of sensitive data from all users except a selected group, or you may want to mask all sensitive data unless a user is specifically allowed to access it.
Learn More
If you would like to learn more about how Satori can help you with streamlining DataSecOps by enabling agile security, governance, and privacy to your Redshift data using Looker, as well as with other data stores and other BI tools, contact us today to set up a demo.