


- Traditional approaches to data access control
- Typical methods for implementing Snowflake Secure Views (with Okta and Tableau)
- The challenges of managing Access Control at scale
- The principles of a scalable data access control system
- Building a 3D context-based access control policy
Why Snowflake?
In this post we’ll focus on a Snowflake data warehouse platform and its respective features due to its widespread use. Nonetheless, the same principles outlined here apply to other DWH platforms like AWS Redshift, GCP Big Query and others…Traditional approaches to data access control
There are many approaches to implementing access controls in a Snowflake environment. The common ground for most of these approaches is the application of RBAC (Role Based Access Control) to securable objects, such as a database, schema, data mart, table, or a view. One of the most common methods is using secured views, which are particularly useful when users need access to a specific dataset without exposing its underlying tables or other structural database details.Typical methods for implementing Snowflake Secure Views (with Okta and Tableau)
Let’s dive into a hypothetical case of a typical Snowflake Access Control implementation using Okta. In this example, Okta is used to assign users with identities using groups and roles and Snowflake Warehouse is used with Secure Views implementation to control access of roles to data. Our situation starts with two groups of data analysts, one British, one French, that can never seem to get along—especially when personal data is involved. The British group (UK in our diagram) is responsible for analyzing the data of customers living in London for the purpose of personalized services tailored to the British market. The French group (FR in our diagram) is responsible for accomplishing the same ends for Parisian customers. To enforce privacy requirements, the data engineering team has created two different secure views on top of the same database schema, each filtering the relevant DB records for the British and French groups respectively so that each group can only access relevant information.
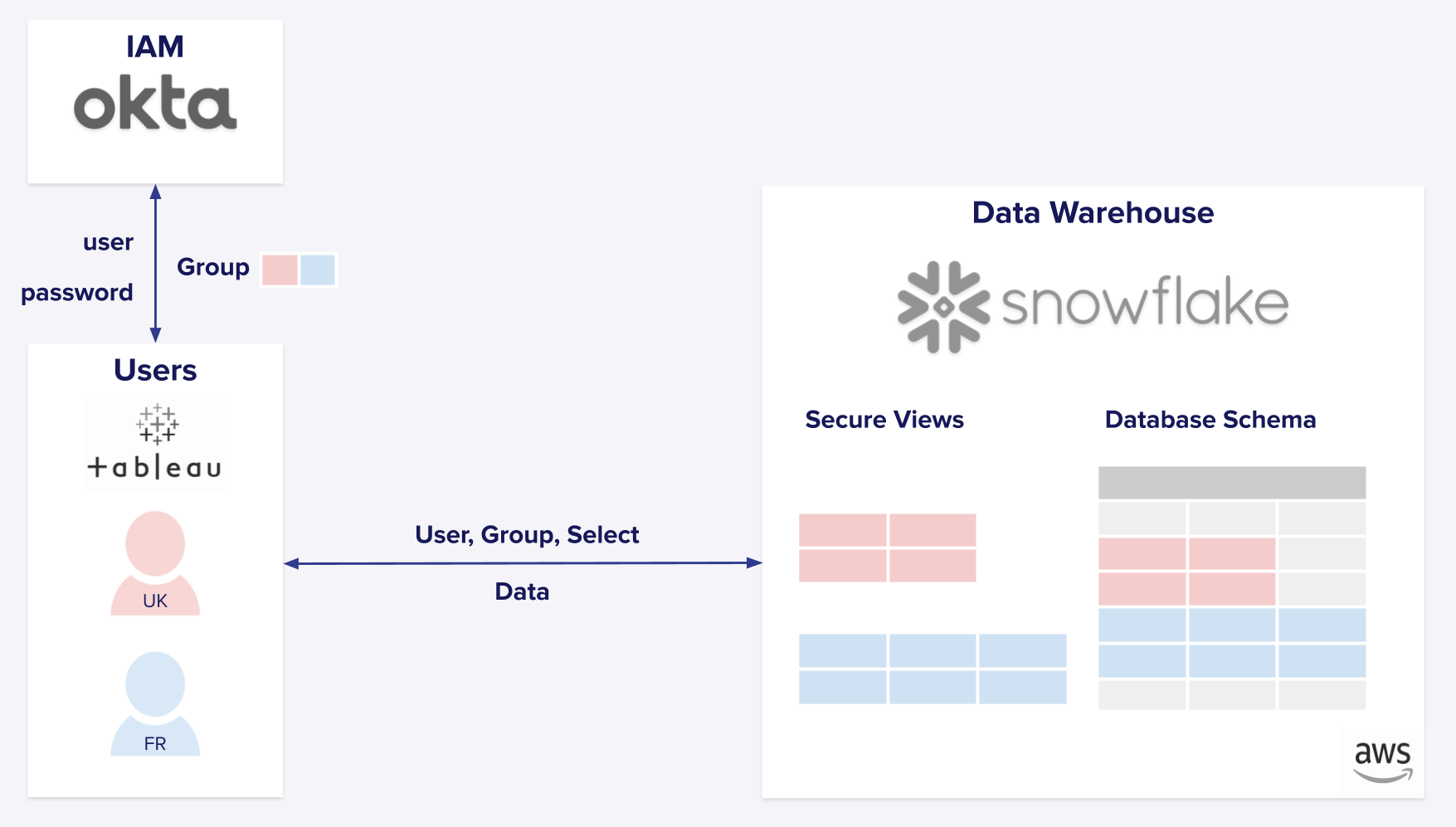
Deploying Satori into a Snowflake environment
The challenges of managing Access Control at scale
Secure Views, like most other technical implementations of access-based approaches, is appropriate and useful when the size of an environment and the number of teams/roles are limited and ״slowly changing”. But when your team and/or environment grows above a certain size, when your data moves between repositories and clouds, when engineers spin up new temporary databases and when the nature of your business requires frequent schema changes, the logical structure of your Secure Views layer breaks or become too hard to maintain.This happens for several reasons:
- It’s a logical layer with a built-in forward compatibility requirement, meaning you have to predict your future data architecture needs. In other words, when you decide to add a new column, your Secure Views may break and require an update.
- Data location is never static; it changes on a daily basis, requiring you to keep updating your views or creating new ones as data moves to new places and repositories.
- It has to natively integrate into your application development life cycle. This means that you end up throwing more controls into your development process, creating additional overhead as a mitigation method for the built-in risk that comes with additional dependencies.
- Changes to your data scientist and analyst teams, hiring of additional talent, organization restructuring and the emergence of new product lines may all have derivatives and implications on the structure and implementation of your Secure Views layer.
The principles of a scalable data access control system
Let’s try to understand what a better alternative can look like. In other words, what design principles should be applied for a scalable data access control system that bypasses the inherent issues described above.- The system should follow a zero duplication principle when it comes to configuration. Most organizations already have a user management system in place, such as IAM (Identity Access Management) solutions, that already contain the required user context in terms of org structure, division, role etc… Therefore, an ideal solution will be able to leverage the existing identity context as defined and maintained in the enterprise IAM solution and will not require the duplication and maintenance of the same configuration elsewhere.
- The system should be data-centric not database-centric. It should be independent of database meta data, schema names, table structure and columns. This is important to ensure that dependencies are eliminated, meaning that the associated overhead with managing changes is non-existent. An ideal system should be able to apply access control to data regardless of the DB schema structure.
- This type of solution should be in-line. Granular user access should be applied in real time (when access to data occurs) while, at the same time, able to enforce policies and block suspected attempts. A deployment that relies on off-line analysis of DB activity or logs may identify suspected access incidents, but it will likely be too late to avoid a data leak or a breach. For these important reasons, it can’t be considered as an appropriate alternative to existing Access Control measures.
- This solution should be embraced by data consumers. Ideally, data users shouldn’t be aware of the access control solution in place. This is important for multiple reasons, the main one being that we wish to avoid negatively impacting user experience so that data scientists are as innovative and productive as possible.
Building a 3D context-based access control policy
To better tackle all of this, and more, Satori Cyber built its Secure Data Access Controller. Let’s review Satori’s design principles to see how our solution can serve our quest for an alternative Access Control solution. Satori’s on a mission to:- Show you who is accessing what data
- Allow you to define and enforce policies for data access
- Alert you to any abnormal activity
- Let you take action in real time
.png)
The Satori conceptual 3D context cube
This three dimensional context is used to apply data access policies that can be detached from a DB schema structure and allow consumers to delineate data access privileges. In other words, our solution provides types of users access to types of data instead of providing role-specific access to Secure Views or other database objects. Now we can make both groups happy.
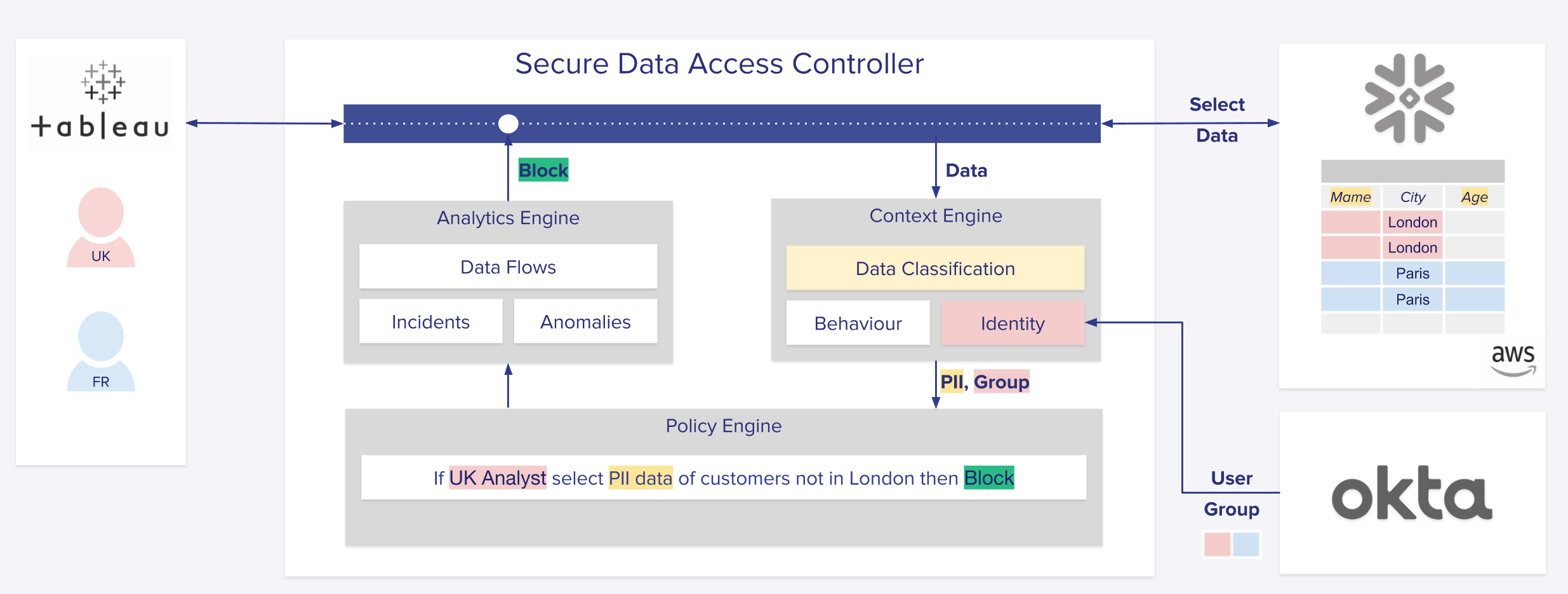
Deploying Satori into a Snowflake environment
This type of architecture fully enables security, privacy and data teams to define business policies that don’t require an intermediate logical layer of Secure Views while keeping data access segregated between the different groups.Going back to the example above, a Satori user can implement the following policy within the Satori management console:
“If UK Analyst selects PII data of customers not in London then Block”
Satori will build the user and data context automatically and classify city addresses out of data records. In the event of a policy violation, the request will be blocked and the user will receive a database error.
Summary
In a broader sense, context-based policies allow team members to access data solely relevant to their geography and restrict access to data outside of that scope. It leverages the group’s structure (AKA user context) as defined in the company’s IAM (Okta in our example) and a team’s data is defined by the type of data that is being accessed and returned. Satori adds relevant identity and data context to every transaction and matches those attributes to the policy. If an employee from the UK team tries to access data from the French project, Satori identifies that that type of data is not authorized for that type of user and can alert, block or modify the response appropriately without having to implement any changes to database structure. This is done completely transparently even if data moves to a different data store. If you struggle with similar challenges, I invite you to get in touch with us. We’d be thrilled to jump on a call and see how we can help protect your data. We also invite you to subscribe to our blog and stay updated on future posts!


